Стратегии : evo_lutio — LiveJournal
В Сети популярна вот эта шутка про стратегии:Но в своей жизни многие люди думают, что стратегии выглядят именно так.
Вчера я по случаю посмотрела начало российского сериала «Короли игры»(2007).
В первые же 10 минут там показали как раз такую вот «стратегию» с ловлей комара на соль, водку, палку и камень.
Короли игры — это команда «стратегов», которые помогают людям достигать желаемого, когда им уже отказали.
То есть эта команда создает такой контекст, чтобы воля других разворачивалась в пользу клиента.
Но это по задумке. А в реализации у этой команды получается как раз ловля комара на соль, воду, палку и камень.
Самая первая ситуация — дочь состоятельной матери, которая против маминой воли хочет увеличить грудь силиконовыми имплантами.
Мать не может ее отговорить и нанимает супер-стратегов, чтобы они помешали планам дочки.
Дальше разворачивается настоящий квест.
Дочь едет на операцию, подходит к остановке и там сидит один из команды, громко рассказывая «приятелю» про какую-то свою девушку.
Приятель громко интересуется, какая же у его девушки грудь.
«Грудь супер, — кричит стратег, чтобы услышала девушка. — Маленькая, настоящая, без силикона!»
Наевшись соли вместо сахара, наш комар, то есть нерадивая дочь своей матери, садится в автобус. Воля ее пошатнулась, мучают сомнения и информационная жажда, она жадно шарит глазами по автобусу и читает на обложке журнала, который ей сунули под нос все те же хитрые «стратеги»: «Риски пластической хирургии!».
В глазах ее троится, будто она хлебнула водки вместо воды.
Жажду свою она не утолила, а лишь расшатала себя больше.
В расшатанном состоянии она добрела до клиники. И что же? Врач опаздывает.
Мы видим, что врачу искусственно создали препятствие, выследив его машину и устроив аварию на дороге.
И вот об это препятствие, об эту услужливо подложенную палку, спотыкается наш расшатанный комар.
Пока героиня сомневается ждать врача или нет, ее добивают камнем.
К ней выходит еще один «стратег», назвавшись юристом клиники, он провожает ее в кабинет и зачитывает ей договор, где перечислены послеоперационные ужасы, за которые клиника не несет ответственности. Выслушав список возможных уродств и болезней, девушка больше не хочет силиконовую грудь. Ее комар, то есть желание импланта, подыхает.
Выслушав список возможных уродств и болезней, девушка больше не хочет силиконовую грудь. Ее комар, то есть желание импланта, подыхает.
Как же стратегу удалось захватить кабинет неприятеля на глазах администратора?
А он прикинулся газовой службой, получил ключи и дальше уже разыграл этот спектакль, пока администратор болтала по телефону.
Точно так же, как и в истории с комаром, хватило бы одного юриста, одного камня, а лучше свернутой газеты, которым его можно было прихлопнуть. Но «короли игры» не ищут легких путей, их стратегия должна быть максимально сложной и запутанной, включать в себя множество каскадерских трюков, часть из которых будут выполнять жертвы.
Комар должен обязательно поесть соли, потом обязательно напиться водки, потом непременно спотыкнуться о палку и, наконец, удариться головой о камень.
Ничего, что в реальности комары не едят соль, не пьют водку, не спотыкаются и не ударяются головой. Автор стратегии представляет на месте комара кого-то вроде себя, но только намного глупей и послушней.
И все стратегии Победителей скроены по этому лекалу.
Чуть проще или такие же сложные, но это всегда история, где нет второго субъекта, а есть лишь послушная проекция самого «стратега».
Совсем другое дело стратеги.
Вот когда хищник оценивает силы неприятеля в этой истории и в этой, он не придумывает за неприятеля его ходов.
В первом случае он видит Выскочку и решает познакомиться поближе, чтобы этой Выскочке подыграть в нужном себе направлении. Не направлять человека, а открыть его решето и посмотреть, что из этого решета может пригодиться.
Во втором случае он смотрит на поле боя дольше, чтобы понять кто с кем в союзе, а кто в оппозиции.
Он сразу увидел, что мать невесты — Штурман, рассмотрел ее характер в динамике, не только персиковое платье, потому что только для моих двоечников персиковое платье означает стремление немедленно отдаться первому встречному, а в жизни все не так. Балкон удобен тем, что видно, кто к кому подходит, кто бегает, кто на месте стоит, кто в стороне, кто в центре. На поле так и надо смотреть, отстраненно, со стороны, представляя, что вы смотрите с балкона или на карту местности. И себя на этом поле тоже нужно видеть так же, как отдельную фигуру, видя слабости вашей позиции и сильные стороны.
На поле так и надо смотреть, отстраненно, со стороны, представляя, что вы смотрите с балкона или на карту местности. И себя на этом поле тоже нужно видеть так же, как отдельную фигуру, видя слабости вашей позиции и сильные стороны.
Хищник не придумывал за мать невесты ее ходы. Он думал лишь о том, чем вызвать ее расположение.
Чтобы вызвать расположение человека, нужно увидеть его интерес.
Люди в короне и с внешним локусом имеют не интерес, а нужду, голод. Вот почему хищник в одну минуту пленяет таких людей.
Люди без короны, с нормальным локусом имеют нормальный интерес. И они тоже проникаются симпатией к рыбаку, а он проникается симпатией к ним, потому что они умеют видеть обратную связь и общаться в границах.
Вот это стратегия, противоположная стратегии Победителя.
Победитель гоняется за человеком с копьем как за добычей, он овеществляет другого. А рыбацкая стратегия — самому предложить добычу, увидев в другом субъекта.
Если другой — Победитель, он сам будет гоняться за рыбаком, сливая все. Только рыбак не возьмет слитое, а хищники могут взять, часть или все, смотря какой хищник, у хищников разная степень этичности.
Только рыбак не возьмет слитое, а хищники могут взять, часть или все, смотря какой хищник, у хищников разная степень этичности.
Если другой имеет нормальный локус контроля, он не будет гоняться с копьем, он попытается предложить встречную добычу и, если рыбаку интересно, возникнет обмен.
С хищником будет то же самое. Если вы не погонитесь за ним, а предложите ему что-то интересное для него, он согласится на равноценный обмен.
То есть хищник — существо безопасное, если у вас нет короны.
Опасен хищник только для человека с большой короной и с плохими границами.
Если хотите, давайте эту тему обсудим.
А еще приведите примеры смешных «стратегий» с женских и мужских тренингов, курсов, из блогов, все равно откуда.
Только ссылки закрашивайте.
Стратегия и искренность : evo_lutio — LiveJournal
Не раз поднимавшаяся, но всегда актуальная тема.
Надо ли стратегу быть искренним? И насколько искренность совмещается со стратегическим поведением?
Отвечу сразу.
Быть искренним надо обязательно всем!
Искренность идеально сочетается со стратегическим поведением, если это именно оно. То и другое тесно связано.
Почему так важно быть искренним?
Всю информацию об отношении к ним других люди воспринимают невербально. По взглядам, интонациями, жестам, движениям, другим нюансам. У людей за время эволюции сформировались огромные возможности для социальной дифференциации, то есть для опознания: свой, чужой, опасный, безопасный, любящий, равнодушный и т.д.
Большую часть воспринятой информации люди не осознают, а чувствуют. И даже чувствуют не все, поскольку психика фильтрует самое актуальное и скрывает стрессогенное. Именно поэтому несчастно влюбленные имеют столько иллюзий. Чем важнее нам отношение человека, тем больше иллюзий, поскольку сильней угроза стресса. Но любой, вышедший из любовной аддикции, может вспомнить и воссоздать параллельный план своих эмоций: он был безмятежен, но одновременно тревожился, он доверял, но одновременно сомневался. Он вытеснял реальное представление, не специально, так получалось само. Это делала за него психика. Тем не менее, чужие эмоции мы отражаем довольно точно, особенно пока человек для нас не очень значим. Отсюда пушкинское: «чем меньше женщину бы любим, тем легче нравимся мы ей». Легче — потому что иллюзий меньше. Хотя эта идея имеет и оборотную сторону: мотивации мало, то есть огня и потока. Наша задача — учиться видеть реальность, имея высокую мотивацию. А не выбирать между онегинской отморозкой и слепым фанатизмом аддикта.
Он вытеснял реальное представление, не специально, так получалось само. Это делала за него психика. Тем не менее, чужие эмоции мы отражаем довольно точно, особенно пока человек для нас не очень значим. Отсюда пушкинское: «чем меньше женщину бы любим, тем легче нравимся мы ей». Легче — потому что иллюзий меньше. Хотя эта идея имеет и оборотную сторону: мотивации мало, то есть огня и потока. Наша задача — учиться видеть реальность, имея высокую мотивацию. А не выбирать между онегинской отморозкой и слепым фанатизмом аддикта.
Но факт остается фактом, люди хорошо чувствуют чужую фальшь. Именно поэтому никогда (никогда) не используйте ни одну рыбацкую технику или инструмент (шары, крючки, пики и т.д.), если это неискренне, если вы не находите горячего отзыва в своей душе. На влюбленного, погруженного в иллюзии человека, это конечно подействует. Но зачем на него действовать? Влюбленные и ругань принимают за шары, то есть способны переворачивать все с ног на голову. И даже влюбленные почувствуют диссонанс, просто не захотят заметить его и осознать. Все остальные и диссонанс почувствуют и неприязнь к вам испытают. То есть инструменты не работают без потока, а поток — это ваши искренние эмоции (влечение, гнев, интерес, радость, печаль и т.д.). Понятно? Не хочется больше это повторять. Не работают инструменты, если вы притворяетесь. Даже у опытных рыбаков не сработают, но они и не будут пытаться варить кашу из топора, если негде раздобыть крупу.
Все остальные и диссонанс почувствуют и неприязнь к вам испытают. То есть инструменты не работают без потока, а поток — это ваши искренние эмоции (влечение, гнев, интерес, радость, печаль и т.д.). Понятно? Не хочется больше это повторять. Не работают инструменты, если вы притворяетесь. Даже у опытных рыбаков не сработают, но они и не будут пытаться варить кашу из топора, если негде раздобыть крупу.
Есть вторая причина, почему надо быть всегда искренним. Это важно ради самоуважения. Если вы изображаете чувства и эмоции, которых не испытываете, вы предаете себя. Вы — это ваши чувства и эмоции, и если вы притворяетесь, вы дистанцируетесь от себя, запираете себя в темный чулан и живете без себя, бездушной оболочкой. Ради чего вы это делаете? Чтобы получить выгоду? Во-первых, не выйдет, см. выше. Во-вторых, эту выгоду получили бы не вы, вы же заперты в темном чулане.
Поэтому никогда не притворяйтесь. Будьте искренними.
Теперь о том, как это сочетается со стратегическим поведением. Точнее не так. Почему только это и сочетается со стратегическим поведением?
Точнее не так. Почему только это и сочетается со стратегическим поведением?
По тем же причинам, которые выше описаны. Действуя искренне, вы действуете в потоке, вы сильней и вы не вызываете в людях ощущение фальшивки, вранья, диссонанса между вашей вербаликой и невербаликой. Вам доверяют и правильно делают, вы искренни. Обратите внимание на это слово «искренность». Вы искритесь энергией, когда действуете и говорите искренне. Даже самые гениальные лжецы и авантюристы действовали искренне, поскольку верили сами в свою ложь до самой глубины души. Но это отдельная, скользкая тема, можно ли добиться искренности, виртуозно обманув себя. Большинству людей это не под силу. И это неэкологично, по отношению к себе в первую очередь. Как-нибудь потом разберем эти случаи. Пока остановимся на том, что вы должны чувствовать все, что говорите и делаете. Не играть чужих ролей.
Почему же люди сомневаются, что искренность и стратегия совместимы?
Из-за разрыва между эмоциями и рассудком._27.png) Из-за того самого «ум с сердцем не в ладах». Правильным кажется одно, а хочется другого. Поэтому кажется, что надо выбрать: либо от ума действовать, либо от сердца.
Из-за того самого «ум с сердцем не в ладах». Правильным кажется одно, а хочется другого. Поэтому кажется, что надо выбрать: либо от ума действовать, либо от сердца.
Чтобы учиться рыбалке (и другие ресурсы прокачивать) надо очень твердо понять, что разрыв между умом и сердцем — это ненормальная ситуация, это дефолт Королевы и Короля, это внутренний конфликт. Это частая очень ситуация, но это так же ненормально, как и инфантилизм взрослых. То есть для детского возраста такой разрыв норма, а для взрослой личности — нет. Наша задача помирить ум и сердце, вывести Короля и Королеву в баланс, только тогда будет возможна эго-интеграция и рост личностной силы.
Но важно то, что даже неинтегрированная личность, даже самая инфантильная личность все равно может быть искренней и действовать стратегически, точнее должна быть искренней, когда учится действовать стратегически. И сейчас я покажу, как это нужно делать.
То, что люди называют «искренность» часто состоит из множества противоречивых и быстро сменяющихся эмоций.
Вот Вася и Маша живут в дефолте. Утром Маша хочет Васю придушить подушкой, вспоминая вчерашнее. Потом отвлекается от обиды и начинает бояться, что он не наденет шарф и простынет. На работе переживает о своей утренней злобе и искренне любит Васю. После обеда, глядя на атлетичного коллегу, думает о том, как ей Вася надоел в сущности и какой же он урод. К вечеру начинает переживать, что Вася вернется домой слишком поздно и она будет изводиться от ревности. А когда Вася возвращается домой вовремя, она думает, что слишком рано вышла замуж и не за того.
В какой момент Маша искренне чувствует? Во все моменты разом. Ее эмоции это противоречивый, разнонаправленный поток. Более того, этот поток может много раз смениться не за день, а во время одного короткого диалога с Васей, от любви до ненависти.
Некоторые думают, что вести себя абсолютно искренне, это каждую минуту демонстрировать изменения своих эмоций. Но представьте себе, во что тогда превратится жизнь Маши, если она будет обо всех своих переменах Васе сообщать. «Знаешь, Вася, хочу быть честной с тобой, я тебя ненавижу». «Вася, должна тебе признаться, что никакой ненависти сейчас не чувствую, наоборот думаю, как бы укрепить наш брак». «Вася, ты лучший из мужчин, клянусь». «Вася, ты урод и проходимец, честное слово».
«Знаешь, Вася, хочу быть честной с тобой, я тебя ненавижу». «Вася, должна тебе признаться, что никакой ненависти сейчас не чувствую, наоборот думаю, как бы укрепить наш брак». «Вася, ты лучший из мужчин, клянусь». «Вася, ты урод и проходимец, честное слово».
Собственно, примерно такое и происходит во многих парах, где люди настолько инфантильны, что считают важным сообщить назначенной мамочке в лице партнера обо всех своих переживаниях и ощущениях. Оставьте в покое человека, ироды, смилуйтесь. Искренность и постоянный поток детских экскрементов не имеют ничего общего.
Если вы противоречивы и переменчивы в эмоциях, но хотите научиться действовать стратегически, вам нужно выбрать ту эмоцию, которая, во-первых, наиболее стабильна, во-вторых, соответствует цели стратегии. То есть если вы решили улучшить брак с Васей, вы должны выбрать из вороха своих эмоций любовь к нему. Бывает любовь? Если нет или очень редко, стратегию на этом не построишь. Потока нет. Нет крупы для каши. Если любовь бывает нередко, можно пробовать, но только эту эмоцию придется сделать стабильней и держать свой поток в ее русле.
То есть начинающий стратег (рыбак) от рыбы отличается тем, что сам выбирает русло. Смотрите, он не роет канал (это уровень высшего мастерства, мы о таком пока и говорить не будем, но конечно и там нет притворства никакого, должен начаться реальный поток в вырытом канале), он выбирает то русло, которое УЖЕ есть и которое вполне глубоко, то есть в нем есть такая эмоция, часто, сильно, но нестабильно. Если его поток то и дело меняет русло, разворачивается или застревает в плотинах, он направляет этот поток в русло нужной ему эмоции и старается держать.
Как направляется и держится поток?
Если наша Маша решила выйти из дефолта с Васей, поняв, что, хоть он и урод, но дорог ей и все еще любим, она должна остановить свои качели и перестать метаться. Пока она мечется, надеясь втайне, что Вася ее отловит и убедит, что им надо быть вместе, Вася ведет себя все хуже. Дефолт постепенно разрушает связь Маши и Васи, поскольку природа стремится к равновесию. Если пара не выходит в баланс, она какое-то время мучает друг друга в дефолте, а потом расстается. Или расходится по комнатам и живет как соседи, что тоже по сути- развод. Если Маша не хочет доверять дефолту разрушить ее брак, а хочет сама поучаствовать как личность (а не бревно в реке) и стратегическим путем выйти из дефолта, она должна остановить свои эмоциональные качели изнутри и сфокусироваться на любви к Васе.
Или расходится по комнатам и живет как соседи, что тоже по сути- развод. Если Маша не хочет доверять дефолту разрушить ее брак, а хочет сама поучаствовать как личность (а не бревно в реке) и стратегическим путем выйти из дефолта, она должна остановить свои эмоциональные качели изнутри и сфокусироваться на любви к Васе.
Обратите еще раз внимание. Если любви к Васе уже нет, притворяться не надо. Надо быть честной и смелой. Не получится ничего, только самоуважение упадет еще ниже и энергии станет меньше. Но если любовь к Васе есть и занимает среди других эмоций важное место, не где-то в дальнем углу пробуждается раз в сто лет, а достаточно громко звучит в сердце Маши, она может попытаться держать свой поток в этом русле, не давая ему все время менять направление.
Это делается достаточно легко на самом деле и вы это делаете постоянно, просто не осознаете, не управляете этим сами, опираетесь на внешнее. Вы собираете женсоветы или мальчишники, чтобы услышать чужое мнение и перестать метаться, пожить хотя бы несколько часов в непротиворечивом состоянии. То есть пока вы так мечетесь, любое мнение, особенно логично сформулированное или от человека, которого вы цените, направляет ваш поток и держит какое-то время в одном русле. Подружка говорит Маше, что Вася совсем обнаглел и надо срочно завести любовника. И Маша решает, да, заведу, ей и самой уже такие мысли приходили, поэтому она начинает думать о любовнике. Потом, через какое-то время, опять может начать бояться Васю потерять и мечтать укрепить брак. Васе приятель говорит, что с Машей надо пожестче, запретить ей пилу и скалку. Вася согласен, он и сам об этом думал, он решает поменять линию поведения на более жесткую. Но потом может опять усомниться и испугаться, что Маша обидится и любовника заведет для утешения. В общем, пока люди на качелях, они очень внушаемы и поддаются влиянию со стороны. Внутренней стабильности нет, качает от любого ветра.
То есть пока вы так мечетесь, любое мнение, особенно логично сформулированное или от человека, которого вы цените, направляет ваш поток и держит какое-то время в одном русле. Подружка говорит Маше, что Вася совсем обнаглел и надо срочно завести любовника. И Маша решает, да, заведу, ей и самой уже такие мысли приходили, поэтому она начинает думать о любовнике. Потом, через какое-то время, опять может начать бояться Васю потерять и мечтать укрепить брак. Васе приятель говорит, что с Машей надо пожестче, запретить ей пилу и скалку. Вася согласен, он и сам об этом думал, он решает поменять линию поведения на более жесткую. Но потом может опять усомниться и испугаться, что Маша обидится и любовника заведет для утешения. В общем, пока люди на качелях, они очень внушаемы и поддаются влиянию со стороны. Внутренней стабильности нет, качает от любого ветра.
Для стратега важна воля (стратегическое поведение — это проактивное, а проактивность — это и есть воля, саморегуляция на внутреннем круге ресурсов в моей книге «Любовь: секреты разморозки»). Воля помогает человеку не метаться от эмоции к эмоции, а выбрать что-то одно и держать на этом фокус внимания.
Воля помогает человеку не метаться от эмоции к эмоции, а выбрать что-то одно и держать на этом фокус внимания.
Маша должна выбрать, либо она разводится с Васей и тогда направить свою стратегию на организацию самостоятельной жизни, либо она пытается выйти из дефолта и тогда направляет стратегию на построение отношений с Васей. Пока же она мечется от «Ты мне надоел» до «Я не хочу тебя терять», стратегии не будет. Представьте себе этого полководца, который командует войску то наступать, то отступать, то снова наступать.
И самое важное здесь, что пока люди на качелях, у них не только стратегии нет, но и искренности нет тоже. Ну какая искренность, если пять минут назад признавался в любви, а сейчас прогоняет? Кто поверит в искренность такого человека? Он и сам не верит себе, поскольку чувствует, насколько его эмоции переменчивы, не видит, что они настоящие, глубокие, сильные. Искренности нет при поверхностных эмоциях! Искренность появляется, когда ваша эмоция становится стабильной и превращается в чувство.
То есть искренности у непроактивной, инфантильной личности нет вообще, есть какой-то сумбур внешних влияний и хаотичных реакций.
А стратегическое поведение помогает стать действительно искренним, сделать эмоции сильными и осознанными, укрепиться в своем отношении. А потом, благодаря стратегии, выстраивается новая ситуация отношений, которая поддерживает чувства, сама по себе тоже делает вашу искренность (и искристость) больше. То есть если Маше удастся выйти из дефолта, если они помирятся с Васей и перестанут друг друга обижать, ее отношение к нему станет стабильно хорошим, для качелей не останется места.
Но обратите внимание: если во время выхода из дефолта у Маши не получится быть искренне любящей, хотя бы искренне симпатизирующей, а придется частенько притворяться, у нее тоже ничего не получится. Притворство не работает, поскольку энергии не имеет. Поэтому если вы пытаетесь держать фокус на эмоции, но у вас не выходит (например Маша пытается любить Васю, но он ее постоянно бесит, пытается его хотеть, но он ее отвращает), вам нужна другая стратегия, эту вы не тянете, нет для нее потока, цель нужна попроще. Например, не вернуть страсть, а просто наладить для начала миролюбивое соседство, исходите из своих возможностей, то есть слушайте сердце свое — это банк энергии, а рассудок всего лишь казначей.
Например, не вернуть страсть, а просто наладить для начала миролюбивое соседство, исходите из своих возможностей, то есть слушайте сердце свое — это банк энергии, а рассудок всего лишь казначей.
Друзья, у вас получается стратегическое поведение? Есть успехи?
Я в соцсетях:
Evolution / Эволюция : nastolki — LiveJournal
Только ленивый еще не написал про одну из самых успешных и умных российских настольных игр. Сегодня мы присоединимся к их числу. Вручаем игре орден «Золотого гекса» и предлагаем вам почитать про нее и все дополнения!| Русское название: Эволюция Зарубежное название: Evolution, Evolution. The origin of species Геймдизайнер: Дмитрий Кнорре Тип: карточная Сайт: http://rightgames.ru/ | Число игроков (и оптимальное): 2-4 (4) Сложность освоения: низкая Время подготовки: 5-15 минут Время партии: 30-60 минут |
Чем больше мы познаем неизменные законы природы, тем более невероятными становятся для нас чудеса.  Чарльз Роберт Дарвин |
Авторы статьи: Александр flaring_tille Бабулин и Ольга hvatograf Воронова
Представьте себе Лох-несское чудовище: двадцать метров длиной; с длинных и острых, словно мачете, зубов, капает яд; под изъеденной паразитами кожей скрывается толстенный слой жира; на охоту оно всплывает из неведомых глубин; не брезгует падалью. А в случае опасности готово скрыться в норке. Вы себе это представляете? Думаете, природа могла бы допустить существование подобного монстра? Едва ли. Но в игре «Эволюция» вы можете себе позволить поспорить с природой…
Происхождение видов
Все тяготы естественного отбора сокрыты в небольшой коробочке зеленого цвета. Там — столь же простой, как природные механизмы, инвентарь: 84 карты из глянцевого картона, 25 фишек еды разного цвета, 2 кубика, пара страничек с правилами.
Это интересно: игру создал настоящий биолог, выпускник биофака МГУ Дмитрий Алексеевич Кнорре, в настоящее время работающий научным сотрудником НИИ физико-химической лаборатории. Он рассматривает ее как способ популяризации любимой науки.
Он рассматривает ее как способ популяризации любимой науки.
Все карточки — двусторонние. С одной стороны — идентичные «ящерки», обозначающие в игре животное без дополнительных свойств. С другой — одно-два свойства, которыми можно наделить зверя. Или рыбу, земноводное, птицу — как пожелаете.
Каждый ход в игре состоит из четырех фаз. Перед первой фазой первого хода каждому игроку выдается по шесть карт. Далее каждый участник создает своих животных с неограниченным количеством не повторяющихся свойств. Существо может быть хищное (то есть поедать других животных, выложенных на столе), большое, водоплавающее, быстрое, ядовитое и так далее. Доступно пятнадцать различных свойств, которые можно применить к своему питомцу. Одну особенность можно «подарить» соседскому гаду — скинуть на него паразита, который будет каждый ход требовать себе дополнительно две «еды». Дополнительное питание требуют для себя также хищники и большие животные.
Есть карточки, которые играются сразу на пару своих существ, — симбиоз, сотрудничество и взаимодействие. С их помощью можно создавать на столе пищевые цепи.
С их помощью можно создавать на столе пищевые цепи.
Животные эволюционировали, со стола доносятся рык, тявканье и писк. Пора кормить тварей. Вторая фаза состоит в определении кормовой базы. В игру вступает один или два кубика, в зависимости от числа игроков. По итогам броска выясняем, сколько фишек еды кладется на стол.
Третья фаза — питание. Каждый питается по-своему. Кто-то просто забирает фишки со стола, кто-то ворует фишки у соседей, кто-то ест собратьев, кто-то доедает за хищником. Все как в саванне или тундре.
Сами понимаете, животные в таком режиме выживают далеко не у всех. И даже те, кто не съеден, могут умереть от голода — фишек на всех хватает нечасто. Наступает последняя фаза, вымирание. Разобравшись, кто выжил, а кто отправился на тот свет, каждый игрок получает на одну карточку больше, чем у него осталось подопечных. И все радостно переходят к следующему этапу эволюции.
Игра кончается, когда кончается колода карт. И победителем становится тот, у кого к концу на руках оказывается либо больше всего животных, либо самые «навороченные» звери.
В «Эволюции», несмотря на то что придумана она биологом, а не специалистом по играм, есть простор и для стратегического, и для тактического мышления — это не просто тренажер по эволюционным процессам. Сделанная так, что очевидной дороги к победе в ней быть не может, эта игра, если не сидеть за ней дни напролет, надоест не скоро. И при этом она вполне может привлечь и хардкорного мастера кубика и карточки, и простого смертного.
Увлекательность 2 из 3
достоинства: захватывающе подан эволюционный процесс, игроки постоянно на грани вымирания
недостатки: малое разнообразие действий
Взаимодействие 3 из 3
достоинства: сильная конкуренция, плотное влияние друг на друга
недостатки: все взаимодействие — поедать зверюшек противника
Проработка 3 из 3
достоинства: игра легка в освоении, правила расписаны доступно, игра предельно логична большое влияние случайностей
недостатки: несбалансированные карты, неполная трактовка правил
Атмосфера 2 из 3
достоинства: живая тема игры
недостатки: схематичные картинки
Качество 2 из 3
достоинства: выдержанная стилистика, компактность коробки
недостатки: маловато фишек, непрочная коробка
Вердикт: Спокойная и познавательная игра с мощным биологическим уклоном, которая подойдет всем и каждому.
Автор статьи: Дмитрий pastushok Трубицин
Происхождение видов, если наблюдать за ним в ускоренном темпе, — захватывающий процесс. Драма жизни, полная конфликтов, хитрых решений и неожиданных поворотов. Однако же до сих пор принцип «выживает самый приспособленный» не обретал столь явного воплощения в настольной игре.
Всё, что есть у демиургов в начале «Эволюции», — шесть карт на руках. Любую карту можно сыграть рубашкой вверх как новое животное, а можно — как свойство для уже введённого в игру создания. Каждый ход запас карт игроков возрастает по числу подконтрольных животных. Когда общая колода исчерпана, побеждает владелец наибольшего числа высоко забравшихся по ветвям эволюции существ.
Среди прочих выделяется такое свойство, как хищничество. Изначально животные вынуждены полагаться на милость природы, которая каждый ход дарует урожай — порой щедрый, сулящий процветание всем игрокам, а порой скупой, грозящий смертями от голода. Хищник же заботится о себе сам. Он кормится, нападая на других существ, в том числе тех, что принадлежат чужим игрокам.
Изначально животные вынуждены полагаться на милость природы, которая каждый ход дарует урожай — порой щедрый, сулящий процветание всем игрокам, а порой скупой, грозящий смертями от голода. Хищник же заботится о себе сам. Он кормится, нападая на других существ, в том числе тех, что принадлежат чужим игрокам.
Однако и хищникам живётся нелегко. Cвойства, вроде «быстрое», «ядовитое», «норное», спасают травоядных от посягательств острозубых охотников. А насытиться травой мясоеду проблематично. Так что творить свою фауну следует с прозорливостью и вниманием к текущей среде обитания.
Устройство «Эволюции» располагает к дополнениям. В базовой игре свойств — пара десятков, в то время как природа подсказывает ещё сотни и сотни. Первое расширение, «Время летать», лишь укрепляет ощущение бескрайнего потенциала. Помимо новых свойств, оно радует новыми жетонами пищи, благодаря которым уже шесть игроков могут внести свою лепту в дело развития видов. Оптимальное число для быстрой игры, где ходы стремительно сменяют друг друга, втискивая эпохи в минуты.
И лишь один существенный недостаток мешает водрузить «Эволюцию» на постамент всемирной славы — посредственное оформление. Символические иллюстрации довольно милы, но эта оригинальная и удачная отечественная разработка достойна куда лучшего.
Итог: Игра международного уровня, которой недостаёт только достойного оформления.
Первое официальное дополнение к игре, вышедшее в 2011 году на русском языке, и перевыпущенное также на английском, французском и немецком языках в 2012 году. Дополнение добавляет создаваемым животным новые способности и увеличивает максимальное количество игроков до шести.
«Эволюция. Время летать» — первое дополнение к карточной игре «Эволюция». Включает 42 карты, на оборотной стороне каждой из которых приведено одно из десяти новых свойств. Среди них и давшее название выпуску — «Полёт». Существо с таким свойством не может быть атаковано хищником, у которого столько же или больше свойств. Кроме того, в дополнении представлены свойства, способствующие успешной охоте хищника, новые защитные свойства, новый вид паразита, свойства, необходимые для того, чтобы пережить голодный год и т.
 д.
д.«Время летать» не является самостоятельной игрой, и карты данного выпуска замешиваются в общую с базовым комплектом колоду. При этом число возможных участников расширяется до шести. При игре вдвоём или втроём рекомендуется сократить состав колоды — убрать половину карт, что не сложно, поскольку все карты базового комплекта и дополнения представлены в чётном количестве. Описание с сайта tesera.ru
Автор статьи: Дмитрий rhunwolf Тэлэри
Огромный протоконтинент Пангея распался на две неравные части. Подхваченные извержениями, тайфунами, цунами и общим туристическим ажиотажем, все бросились переселяться. Повсюду кипел великий исход зверей, и каждый чесал задней лапой рога в раздумьях, куда податься: «Лавразия? Гондвана? Океан?»
Оригинальная «Эволюция» ещё в 2010 году поразила нас тем, как можно легко, лаконично и увлекательно переложить борьбу видов в карточную игру. Спрессовывая миллионы лет в минуты, мы создаём новые виды, и продолжаем изменять их. Звери учатся прятаться в норах, плавать или питаться мясом бывших товарищей.
Звери учатся прятаться в норах, плавать или питаться мясом бывших товарищей.
Совсем недавно вышло второе дополнение «Континенты». И вот в нём-то появился принципиально новый игровой уровень. Игровой процесс стал больше похож на реальную эволюцию и обрёл черты стратегии. Вместо одной общей кормовой базы появилось три. Два континента, один побогаче, второй победнее. И колыбель жизни — жестокий мировой океан, в котором нет такого понятия, как урожай, и объём доступной пищи всегда фиксирован.
Мы можем создавать новых зверей на любом континенте. Карты дополнения позволяют мигрировать между ними в поисках лучшей доли. Новые комбинации карт позволяют «передавать» невыгодные свойства другим животным и даже выползать из океана на твердь земную.
Но дополнение не лишено и недостатков. Во первых, поблёкли парные свойства: если один из симбионтов «переезжает» с Гондваны в Лавразию, он теряет связь с другим. Во-вторых, считывать стратегический расклад на столе стало сложнее. Деление на 3 локации происходит только в уме, на практике же каждый игрок раскладывает животных около себя. Из-за этого не всегда можно понять, кто где находится, да и для игры теперь нужно в два раза большее пространства. А в третьих — слабое оформление по-прежнему отделяет «Эволюцию» от титула лучшей российской игры.
ИТОГ: Оригинальная «Эволюция» по праву может называться одной из лучших отечественных настольных игр. Дополнение «Континенты» делает её сложнее и стратегичнее, добавляя в борьбу видов новый аспект — территориальное соперничество.
В 2011 году к игре также вышло неофициальное авторское дополнение «Ледниковый период», добавляющее к игре элемент случайности. Перед каждым ходом разыгрывается карта сил природы. Сайт: http://tesera.ru/game
Эволюция желаний: стратегии выбора потенциальных партнеров
Forbes Woman публикует отрывок из книги Дэвида Басса «Эволюция сексуального влечения. Стратегии поиска партнеров» издательства «Альпина Паблишер».
Как в процессе эволюции формировались требования мужчин и женщин к представителям противоположного пола и их стратегии выбора потенциальных партнеров? Как объяснить с точки зрения развития человечества существование и моногамии, и случайных связей? Как все эти феномены меняются со временем? На эти вопросы в своей книге пытается ответить эволюционный психолог Дэвид Басс. Forbes Woman приводит два отрывка из произведения, в которых автор пытается объяснить, действительно ли стоит винить СМИ и рекламу в возникновении сегодняшних стандартов красоты.
Читатели Forbes Woman могут воспользоваться 10%-ной скидкой на любые книги «Издательской группы «Альпина» по промо-коду forbes до 31 августа 2017 года.
Эволюционные корни мужских требований
Большое значение, которое мужчины придают внешности женщины, — вовсе не общий закон животного мира. У многих других видов, например у павлинов, именно самки оценивают внешность самцов, а не наоборот. Точно так же не универсально мужское предпочтение молодости. Самцы некоторых других приматов, например орангутангов, шимпанзе и японских макак, предпочитают более зрелых самок, которые уже продемонстрировали свои репродуктивные способности, они практически не проявляют сексуального интереса к юным самкам из-за их более низкой фертильности. Мужчины имеют дело с уникальным набором адаптивных задач, и их эволюционная сексуальная психология также уникальна. Они предпочитают молодость из-за центральной роли брака в сексуальном поведении людей. Их предпочтения связаны с будущим репродуктивным потенциалом женщины, а не с возможностью зачатия в данный момент. Они придают так много значения внешности, поскольку она несет большое число надежных признаков репродуктивного потенциала партнерши.
Их предпочтения связаны с будущим репродуктивным потенциалом женщины, а не с возможностью зачатия в данный момент. Они придают так много значения внешности, поскольку она несет большое число надежных признаков репродуктивного потенциала партнерши.
Мужчины всего мира хотят иметь привлекательных, молодых и сексуально верных жен, которые сохраняют верность на протяжении длительного периода. Возникновение этих предпочтений нельзя приписать западной культуре, капитализму, узости взглядов белых англосаксов, СМИ или промыванию мозгов с помощью рекламы. Они универсальны для всех культур, и нет такой культуры, где они бы не присутствовали. Это глубоко укоренившиеся психологические адаптации, которые управляют нашими решениями в сфере поиска партнера, точно так же, как наши эволюционные вкусовые предпочтения определяют решения в сфере питания.
Как это ни странно, предпочтения мужчин-гомосексуалистов лишь доказывают глубину этих возникших в процессе эволюции психологических механизмов. Тот факт, что внешность занимает центральное место в предпочтениях геев, а юность — главный атрибут их стандартов красоты, позволяет утверждать, что даже различия в сексуальной ориентации не могут изменить этих фундаментальных мужских адаптаций.
Тот факт, что внешность занимает центральное место в предпочтениях геев, а юность — главный атрибут их стандартов красоты, позволяет утверждать, что даже различия в сексуальной ориентации не могут изменить этих фундаментальных мужских адаптаций.
Такие предпочтения расстраивают некоторых своей несправедливостью. Мы можем лишь ограниченно изменять свою внешность, и одни люди рождаются, или становятся, более красивыми, чем другие. Красота недемократична. Женщина не может изменить свой возраст, и ее репродуктивная ценность с возрастом снижается гораздо быстрее, чем у мужчин, — эволюция обошлась с женщинами жестоко, по крайней мере в этом отношении. (Далее мы увидим, как эволюция жестоко обошлась с мужчинами, которых в среднем ожидает более ранняя смерть.) Женщины борются с увяданием с помощью косметики, пластической хирургии и занятий фитнесом. Этим пользуется косметическая индустрия, бюджет которой в США составляет $8 млрд в год.
После прочитанной мною лекции о половых различиях предпочтений в отношении партнера одна женщина заметила, что мне не стоит распространяться об этом, поскольку такая информация расстраивает женщин. На ее взгляд, женщинам и без того тяжело живется в мире, где доминируют мужчины, а тут еще ученые с рассказами о том, что их проблемы в сфере поиска партнера связаны с эволюционной психологией мужчин. Однако утаивание правды вряд ли поможет, точно так же, как утаивание предпочтения спелых и сочных фруктов, вряд ли изменит наши пристрастия. Предъявлять мужчинам претензии за то, что они предпочитают красивых, молодых и верных жен, все равно что предъявлять претензии тем, кто ест мясо, за то, что они предпочитают животный белок. Убеждать мужчин в том, что их не должны возбуждать признаки юности и здоровья, все равно что убеждать их не чувствовать сладкий вкус, когда на языке оказывается сахар.
На ее взгляд, женщинам и без того тяжело живется в мире, где доминируют мужчины, а тут еще ученые с рассказами о том, что их проблемы в сфере поиска партнера связаны с эволюционной психологией мужчин. Однако утаивание правды вряд ли поможет, точно так же, как утаивание предпочтения спелых и сочных фруктов, вряд ли изменит наши пристрастия. Предъявлять мужчинам претензии за то, что они предпочитают красивых, молодых и верных жен, все равно что предъявлять претензии тем, кто ест мясо, за то, что они предпочитают животный белок. Убеждать мужчин в том, что их не должны возбуждать признаки юности и здоровья, все равно что убеждать их не чувствовать сладкий вкус, когда на языке оказывается сахар.
У многих сохраняется идеалистическая уверенность в том, что стандарты красоты искусственны и навязываются обществом, что красота — это нечто исключительно поверхностное, что представители разных культур придают очень разное значение внешности и что западные стандарты — порождение СМИ, родителей, цивилизации или прочих социальных факторов. Однако стандарты привлекательности вовсе не искусственны — они отражают признаки молодости и здоровья, а следовательно, репродуктивной ценности. Красота не поверхностна. Она говорит о внутренних репродуктивных способностях организма. Хотя современные технологии репродуктивной медицины помогают женщинам сохранять способность к деторождению в более зрелом возрасте, чем это было возможно в прошлом, мужские предпочтения в отношении женщин с явными признаками репродуктивных способностей продолжают действовать, хотя они и возникли очень давно в мире, который больше не существует.
Однако стандарты привлекательности вовсе не искусственны — они отражают признаки молодости и здоровья, а следовательно, репродуктивной ценности. Красота не поверхностна. Она говорит о внутренних репродуктивных способностях организма. Хотя современные технологии репродуктивной медицины помогают женщинам сохранять способность к деторождению в более зрелом возрасте, чем это было возможно в прошлом, мужские предпочтения в отношении женщин с явными признаками репродуктивных способностей продолжают действовать, хотя они и возникли очень давно в мире, который больше не существует.
Впрочем, культура, экономические условия и технологический прогресс играют важную роль в оценке мужчинами девственности. Там, где женщины менее зависимы от мужчин экономически, как в Швеции, на сексуальную свободу смотрят сквозь пальцы, и мужчины не требуют девственности от потенциальных жен. Эти перемены отражают чувствительность некоторых мужских предпочтений к особенностям культуры и контекста.
Несмотря на культурные вариации, в долговременных отношениях сексуальная верность для мужчин является важнейшим условием. Хотя многие западные мужчины не могут требовать от партнерш девственности, они обычно настаивают на верности. Методы контроля рождаемости, возможно, и сделали это предпочтение неважным с точки зрения гарантии отцовства, но тем не менее оно сохраняется. Мужчины не перестают требовать верности от жен просто потому, что те принимают противозачаточные таблетки. Это постоянство указывает на важность нашей эволюционной сексуальной психологии — психологии, которая возникла с ориентацией на важнейшие условия первобытного мира, но продолжает сохранять свою власть и в нынешнем мире сексуальных отношений.
Влияние СМИ на стандарты красоты
Рекламщики широко эксплуатируют привлекательность красивых молодых женщин. Некоторые даже утверждают, что именно СМИ и Мэдисон-авеню формируют единый стандарт красоты, к которому все должны стремиться. Считается, что реклама внушает неестественные, идеализированные компьютерные образы красоты и заставляет людей стремиться к ним. Такая интерпретация, возможно, в какой-то мере и верна, особенно когда нам демонстрируют неестественно худеньких моделей, однако в то же время она как минимум отчасти ошибочна. Стандарты красоты не являются чем-то необоснованным — это надежные признаки репродуктивной ценности. Рекламщикам ни к чему навязывать нам какие-то стандарты красоты, они просто используют все, что помогает продавать товары. Они сажают юную девушку с чистой кожей и правильными чертами лица на капот автомобиля последней модели или показывают, как несколько привлекательных женщин с любовью смотрят на мужчину, пьющего пиво известной марки, поскольку эти образы включают определенные психологические механизмы мужчин и таким образом помогают продавать машины или пиво, а не потому, что рекламщикам хочется установить определённый стандарт красоты.
Считается, что реклама внушает неестественные, идеализированные компьютерные образы красоты и заставляет людей стремиться к ним. Такая интерпретация, возможно, в какой-то мере и верна, особенно когда нам демонстрируют неестественно худеньких моделей, однако в то же время она как минимум отчасти ошибочна. Стандарты красоты не являются чем-то необоснованным — это надежные признаки репродуктивной ценности. Рекламщикам ни к чему навязывать нам какие-то стандарты красоты, они просто используют все, что помогает продавать товары. Они сажают юную девушку с чистой кожей и правильными чертами лица на капот автомобиля последней модели или показывают, как несколько привлекательных женщин с любовью смотрят на мужчину, пьющего пиво известной марки, поскольку эти образы включают определенные психологические механизмы мужчин и таким образом помогают продавать машины или пиво, а не потому, что рекламщикам хочется установить определённый стандарт красоты.
Тем не менее у медиаобразов, воздействию которых мы ежедневно подвергаемся, есть потенциально опасные последствия. В одном исследовании группам мужчин показывали фотографии очень привлекательных женщин и женщин средней привлекательности, а затем просили оценить преданность своим романтическим партнершам. Мужчины, которые рассматривали фотографии красивых женщин, находили своих партнерш менее привлекательными, чем мужчины, которые рассматривали фотографии женщин средней привлекательности. Еще важнее то, что мужчины из первой группы ниже оценивали свою преданность, удовлетворенность, серьезность и близость отношений со своими реальными партнершами. Аналогичные результаты были получены в другом исследовании, где мужчины рассматривали журнальные фото обнаженных моделей: они также ниже оценивали привязанность к своим партнершам.
В одном исследовании группам мужчин показывали фотографии очень привлекательных женщин и женщин средней привлекательности, а затем просили оценить преданность своим романтическим партнершам. Мужчины, которые рассматривали фотографии красивых женщин, находили своих партнерш менее привлекательными, чем мужчины, которые рассматривали фотографии женщин средней привлекательности. Еще важнее то, что мужчины из первой группы ниже оценивали свою преданность, удовлетворенность, серьезность и близость отношений со своими реальными партнершами. Аналогичные результаты были получены в другом исследовании, где мужчины рассматривали журнальные фото обнаженных моделей: они также ниже оценивали привязанность к своим партнершам.
Причина таких изменений отношения заключается в нереалистичном характере данных изображений. Нескольких привлекательных женщин, снимающихся в рекламе, выбирают из тысяч претенденток. Во многих случаях делаются тысячи фотографий выбранной модели. Известно, например, что в журнале Playboy делают около 6000 снимков девушки, появляющейся на развороте. Из этих тысяч фотографий лишь несколько отбирают для разворота и рекламы. А потом эти снимки обрабатывают в фоторедакторе. В результате мужчины видят не то, что есть в действительности, а искусно обработанные изображения самых привлекательных женщин в самых привлекательных позах на самом привлекательном фоне. Сравните эти фотографии с тем, на что смотрел первобытный мужчина, живший в группе не более чем из 150 человек. Вряд ли в таких условиях ему удавалось видеть сотни или хотя бы десятки привлекательных женщин. Однако, будь у него доступ к множеству привлекательных фертильных женщин, он вполне мог бы захотеть сменить партнершу и его преданность реальной спутнице снизилась бы.
Из этих тысяч фотографий лишь несколько отбирают для разворота и рекламы. А потом эти снимки обрабатывают в фоторедакторе. В результате мужчины видят не то, что есть в действительности, а искусно обработанные изображения самых привлекательных женщин в самых привлекательных позах на самом привлекательном фоне. Сравните эти фотографии с тем, на что смотрел первобытный мужчина, живший в группе не более чем из 150 человек. Вряд ли в таких условиях ему удавалось видеть сотни или хотя бы десятки привлекательных женщин. Однако, будь у него доступ к множеству привлекательных фертильных женщин, он вполне мог бы захотеть сменить партнершу и его преданность реальной спутнице снизилась бы.
У нас те же самые механизмы оценки, которые выработались в древние времена у наших предков. Однако сегодня на эти психологические адаптации воздействуют десятки образов привлекательных женщин, с которыми мужчины ежедневно сталкиваются в нашей визуально насыщенной среде — в интернете, журналах, на рекламных плакатах, телевидении и в кино. Эти образы не соответствуют реальным женщинам в реальной социальной среде. Они, можно сказать, лишают нас адаптаций, выработанных для иных условий поиска партнера. Иногда они способны приносить несчастье, разрушая существующие реальные отношения. Доступ к тысячам объявлений потенциальных партнеров на таких интернет-ресурсах и приложениях, как Tinder, Match.com и OKCupid, может сбивать с толку и заставлять думать, что можно найти кого-то получше, стоит только просмотреть достаточно много вариантов.
Эти образы не соответствуют реальным женщинам в реальной социальной среде. Они, можно сказать, лишают нас адаптаций, выработанных для иных условий поиска партнера. Иногда они способны приносить несчастье, разрушая существующие реальные отношения. Доступ к тысячам объявлений потенциальных партнеров на таких интернет-ресурсах и приложениях, как Tinder, Match.com и OKCupid, может сбивать с толку и заставлять думать, что можно найти кого-то получше, стоит только просмотреть достаточно много вариантов.
Под влиянием этих образов мужчины теряют удовлетворенность и преданность существующим партнершам. Они потенциально вредны и для женщин, так как вызывают бесконтрольное и нездоровое состязание за идеальную фигуру, которая якобы привлекательна для мужчин, но на деле далека от того, что предпочитает большинство. Беспрецедентный уровень распространения расстройств пищевого поведения, таких как нервно-психическая анорексия, а также расцвет пластической хирургии, например абдоминопластика и увеличение груди, в определенной мере зависят от этих медиаобразов. Некоторые женщины идут на немыслимые жертвы, чтобы стать тем, что они считают мужским идеалом. Но к таким последствиям при- водит вовсе не создание каких-то новых стандартов красоты. Стандарты женской красоты у мужчин существуют давно, так же как и механизмы соперничества за партнера у женщин, а СМИ просто эксплуатируют их с невиданным и нездоровым размахом.
Некоторые женщины идут на немыслимые жертвы, чтобы стать тем, что они считают мужским идеалом. Но к таким последствиям при- водит вовсе не создание каких-то новых стандартов красоты. Стандарты женской красоты у мужчин существуют давно, так же как и механизмы соперничества за партнера у женщин, а СМИ просто эксплуатируют их с невиданным и нездоровым размахом.
Какую бы роль ни играла красота тела и лица в мужских предпочтениях, эти качества помогают решить только один набор адаптивных задач, стоящих перед мужчинами, — поиск способных к деторождению женщин и вступление с ними в сексуальный контакт. Однако выбор репродуктивно ценной партнерши не гарантирует, что эта ценность будет принадлежать только одному муж- чине. Следующая важнейшая адаптивная задача — гарантия отцовства.
Список игр на ПК про эволюцию
Sid Meiers Сivilization 4: Beyond the Sword
Год выхода: 2007
Платформы: MacOS, на ПК
Системные требования: низкие
Жанр: стратегия
Civilization IV: Beyond the Sword является вторым дополнением культовой игры Civilization IV, где появилось много незначительных, но приятных изменений. По традиции новации не затронули главных моментов игры, а сама она сделана на высоком уровне…
По традиции новации не затронули главных моментов игры, а сама она сделана на высоком уровне…
85 /100
Sid Meiers Civilization 4
Год выхода: 2005
Платформы: MacOS, на ПК
Системные требования: низкие
Жанр: стратегия
Sid Meiers Civilization IV очередная история в цепочке пошаговых стратегий от Сида Мейера. От вас требуется развить собственную империю, преодолев дорогу длиною в несколько веков…
83 /100
Sid Meiers Civilization 4: Warlords
Год выхода: 2006
Платформы: MacOS, на ПК
Системные требования: низкие
Жанр: стратегия
Civilization IV: Warlords это первое дополнение культовой игры Civilization IV. В игру было добавлено много новшеств. Добавлены шесть цивилизаций со своими новыми и неповторимыми юнитами и постройками…
82 /100
Sid Meiers Alpha Centauri
Год выхода: 1999
Платформы: MacOS, на ПК
Системные требования: низкие
Жанр: стратегия
Фантастическое будущее предстает перед нами. Люди Земли создают необычайно большой космическая корабль. Специально отобранная команда уже на пути к новой планете. Это шанс сохранить человечество от исчезновения…
Люди Земли создают необычайно большой космическая корабль. Специально отобранная команда уже на пути к новой планете. Это шанс сохранить человечество от исчезновения…
81 /100
Age of Empires 2
Год выхода: 1999
Платформы: MacOS, PlayStation 2, на ПК
Системные требования: низкие
Жанр: строительство, стратегия
Age of Empires II: The Age of Kings это очередная часть полюбившейся всем Age of Empires. Действия игры простираются на многие тысячи лет. Для управления доступны 13 наций, с которыми вы сможете пройти все эпохи развития…
81 /100
Sid Meiers Civilization
Год выхода: 1991
Платформы: MacOS, на ПК
Системные требования: неизвестно
Жанр: стратегия
Civilization — это известная серия пошаговых стратегий. В начале 90-х американец Сид Мейер создал первую игру этой серии, и Sid Meiers Civilization завоевала популярность среди геймеров…
79 /100
Sid Meiers Civilization 3
Год выхода: 2001
Платформы: MacOS, на ПК
Системные требования: низкие
Жанр: стратегия
Sid Meiers Civilization III это TBS компьютерная игра, разработанная компанией Firaxis Games, и являющаяся сиквелом ко второй части серии игр от Sid Meier. В новой версии Civilization III Вы сможете управлять избранной Вами нацией, а также преодолеете тяжелый путь от зарождения цивилизации и до ее золотого века…
В новой версии Civilization III Вы сможете управлять избранной Вами нацией, а также преодолеете тяжелый путь от зарождения цивилизации и до ее золотого века…
79 /100
Sid Meiers Civilization 5
Год выхода: 2010
Платформы: MacOS, на ПК
Системные требования: средние
Жанр: стратегия
В игре Sid Meiers Civilization V разработчиками воплощено много новшеств. Полностью изменилась методика ведения боевых действий, углубилась система дипломатических связей…
79 /100
Sid Meiers Civilization 3: Conquests
Год выхода: 2002
Платформы: на ПК
Системные требования: низкие
Жанр: стратегия
По сути это второе дополнение к Civilization III в которое включен его предыдущий аддон — Play the World. Название связано с историческими событиями человечества разных эпох, которым посвящены новые девять сюжетов…
78 /100
Sid Meiers Civilization 3: Play the World
Год выхода: 2003
Платформы: на ПК
Системные требования: низкие
Жанр: стратегия
Для популярной глобальной стратегии Civilization III Сида Майера первым дополнением стала игра Civilization III: Play the World. В ней впервые открылись перед игроками новые возможности сражения с настоящими живыми соперниками по сети, для того, чтобы определить самого лучшего мирового правителя…
В ней впервые открылись перед игроками новые возможности сражения с настоящими живыми соперниками по сети, для того, чтобы определить самого лучшего мирового правителя…
78 /100
Sid Meiers Civilization 2
Год выхода: 1996
Платформы: MacOS, PlayStation, на ПК
Системные требования: низкие
Жанр: стратегия
Такая игра, как Sid Meiers Civilization II – это долгожданное продолжение первой части игры, заслуживающее безраздельного внимания. Если сравнивать с предыдущей частью, то в Civilization 2 существенно улучшилась графика, были добавлены юниты, включены новые технологии, цивилизации и части света…
77 /100
Sid Meiers Civilization 4: Colonization
Год выхода: 2008
Платформы: MacOS, на ПК
Системные требования: низкие
Жанр: стратегия
Civilization IV: Colonization — это третий ремейк очень популярной и любимой многими игры Colonization. Вы становитесь главой одной из четырех наций Европы. Вам необходимо создать очень сильную и независимую колонию, которая затем объявит себя новым могущественным государством…
Вам необходимо создать очень сильную и независимую колонию, которая затем объявит себя новым могущественным государством…
75 /100
Age of Empires 3
Год выхода: 2005
Платформы: MacOS, на ПК
Системные требования: низкие
Жанр: строительство, стратегия
Age of Empires III — это свежая версия знаменитой серии Age of Empires. Здесь предлагается руководить могущественной европейской державой. Можно встать у руля одной из 8 стран: Турции, Германии, Франции, Португалии, Англии, Голландии, России, Испании…
75 /100
Plague Inc
Год выхода: 2015
Платформы: на ПК
Системные требования: низкие
Жанр: головоломка, тайм менеджмент
Plague Inc: Evolved очень своеобразная игра жанра стратегия, симулятор. Выглядит как довольно подробная карта Земли. Выступая в роли возбудителя эпидемии игрок должен уничтожить население планеты…
75 /100
Age of Empires III: Definitive Edition
Год выхода: 2020
Платформы: на ПК
Системные требования: высокие
Жанр: градостроительный симулятор, стратегия
Age of Empires III: Definitive Edition — это стратегическая компьютерная игра в реальном времени, разработанная студиями Tantalus Media и Forgotten Empires и изданная Xbox Game Studios. ..
..
75 /100
World of Tanks
Бесплатный
сервер
Год выхода: 2011
Платформы: на ПК, Xbox 360, Xbox One
Системные требования: средние
Жанр: боевик, шутер, экшен, симулятор
World of Tanks — командная тактическая ММО-игра, основным боевым инструментом и средством передвижения которой является танк. Для выбора доступно более 150 бронированных крошек с американских, немецких и советских танкостроительных заводов…
86 /100
Страницы: 1 2 3
Стратегия vs. бизнес-модель: эволюция и дифференциация | Орехова
1. Ансофф И. Стратегический менеджмент. Классическое издание. — СПб.: Питер, 2009.
2. Березной А.В. Инновационные бизнес-модели в конкурентной стратегии крупных корпораций // Вопросы экономики. — 2014. — No 9. — С. 65–81.
3. Гурков И. Б. Стратегический менеджмент организации. 2-е изд. — М.: ТЕИС, 2004.
4. Джонсон Дж., Хафф А.С. Повседневная инновация/повседневная стратегия // Хэмел Г. , Прахалад К., Томас Г., О`Нил Д. Стратегическая гибкость / пер. с англ. — СПб.: Питер, 2005.
, Прахалад К., Томас Г., О`Нил Д. Стратегическая гибкость / пер. с англ. — СПб.: Питер, 2005.
5. Катькало В. С. Исходные концепции стратегического управления и их современная оценка // РЖМ. — 2003. — No 1. — С. 7–30.
6. Катькало В.С. Эволюция теории стратегического управления. — СПб.: Изд-во «Высшая школа менеджмента», 2006.
7. Климанов Д. Е., Третьяк О. А. Бизнес-модели: основные направления исследований и поиски содержательного фундамента концепции // Российский журнал менеджмента. — 2014. — Т. 12. — No 3. — С. 107–130.
8. Котельников В. Ю. Новые бизнес-модели для новой эпохи быстрых перемен, движимых инновациями. — М.: Эксмо, 2007.
9. Лафта Дж. К. Эффективность менеджмента организации. — М.: Русская Де- ловая Литература, 1999.
10. Медведев А. Г. Международный менеджмент: стратегические решения в многонациональных компаниях: учебник. — СПб.: Изд-во «Высшая школа менеджмента», 2014.
11. Орехова С. В. Промышленные предприятия: электронная vs. традиционная бизнес-модель // Terra Economicus. — 2018a. — Т. 16. — No 4. — С. 77–94.
— 2018a. — Т. 16. — No 4. — С. 77–94.
12. Плахин А. Е. Методология адаптивного управления промышленной парковой структурой на основе стейкхолдерского подхода // Вестник Воронежского государственного университета инженерных технологий. — 2018. — No 80(4). — С. 371–377.
13. Пономарев А. Т. Проблемно-ориентированная методология стратегического целеполагания как условие прогрессивного развития общества: социально-экономическое развитие (ч. 2) // Вопросы безопасности. — 2017. — No 4. — С. 1-12.
14. Прахалад К., Хамел Г. Ключевая компетенция корпорации // Вестник Санкт-Петербургского университета. Сер. 8. — 2003. — Вып. 3. — No 24. — С. 23–46.
15. Романова О. А. Эволюция институтов реализации современной промышленной политики // Управленец. — 2019. — Т. 10. — No 3. — С. 14–24.
16. Силин Я.П., Анимица Е.Г. Контуры формирования цифровой экономики в России // Известия Уральского государственного экономического университета. — 2018. — Т. 19. — No 3. — С. 18−25.
17. Стрекалова Н. Д. Концепция бизнес-модели: методология системного анализа // Известия Российского государственного педагогического университета им. А. И. Герцена. — 2009. — No 92. — С. 95–105.
Стрекалова Н. Д. Концепция бизнес-модели: методология системного анализа // Известия Российского государственного педагогического университета им. А. И. Герцена. — 2009. — No 92. — С. 95–105.
18. Третьяк О.А., Климанов Д.Е. Новый подход к анализу бизнес-моделей // Российский журнал менеджмента. — 2016. — Т. 14. — No 1. — С. 115–130.
19. Фролова Л. В., Кравченко Е. С. Формирование бизнес-модели предприятия. — К.: Центр учебной литературы, 2012.
20. Чесбро Г. Открытые бизнес-модели. IP-менеджмент. — М.: Поколение, 2008.
21. Чугумбаев Р. Р. Эталонное управление на основе бизнес-модели совершенства // Учет. Анализ. Аудит. — 2016. — No 1. — С. 58–34.
22. Шерешева М. Ю. Формы сетевого взаимодействия компаний. — М.: ГУ ВШЭ, 2010.
23. Abell D.F. Managing with Dual Strategies: Mastering the Present; Preempting the Future. — N. Y.: Free Press, 1999.
24. Abdelkafi N., Täuscher K. Business models for sustainability from a system dynamics perspective // Organization & Environment. — 2016. — Vol. 29. — P. 74–96.
— 2016. — Vol. 29. — P. 74–96.
25. Amit R., Zott C. Value creation in e-business // Strategic Management Journal. — 2001. — Vol. 22. — P. 493–520.
26. Andrews K. R. The Concept of Corporate Strategy. — Homewood, IL: Dow Jounes-Irwin, 1971.
27. Ansoff H.I. Corporate Strategy: An Analytical Approach to Business Policy for Growth and Expansion. — N. Y.: McGraw-Hill Book Co., 1965.
28. Baden-Fuller C., Giudici A., Haefliger S., Morgan M. S. Ideal types, values, profits and technologies. — L.: London School of Economics, 2015.
29. Baden-Fuller C., Haefliger S. Business models and technological innovation // Long Range Planning. — 2013. — Vol. 46. — P. 419–426.
30. Barlett C., Ghoshal S. Managing Across Borders: The Transnational Corporation. — Cambridge, MA: Harvard Business Review Press, 1989.
31. Bocken N. M. P., Short S., Rana P., Evans S. A literature and practice review to develop sustainable business model archetypes // Journal of Cleaner Production. — 2014. — Vol. 65. — P. 42–56.
— 2014. — Vol. 65. — P. 42–56.
32. Burney J.B. Firm recourses and sustained competitive advantage // Journal of Management. — 1991. — Vol. 17. — No. 1. — P. 99–120.
33. Casadesus-Masanell R., Ricart J. From strategy to business models and to tactics // Long Range Planning. — 2010. — Vol. 43. — P. 195–215.
34. Chandler A. D., Jr. Strategy and Structure: Chapters in the History of American Enterprise. — Cambridge, MA: MIT Press, 1962.
35. Chesbrough H. Business model innovation: It’s not just about technology anymore // Strategy & Leadership. — 2007. — Vol. 35. — No. 6. — P. 12–17.
36. Chesbrough H., Minin A. di, Piccaluga A. Business model innovation path. In: Cinquini L., Minin A. di, Varaldo R. (eds). New business models and value creation: A service science perspective. — Milano: Springer-Verlag, 2013.
37. Chesbrough H., Rosenbloom R. The role of the business model in capturing value from innovation: Evidence from Xerox Corporation’s technology spin-off companies // Industrial and Corporate Change. — 2002. — Vol. 11. — P. 529–555.
— 2002. — Vol. 11. — P. 529–555.
38. Demil B., Lecocq X. Business model evolution: In search of dynamic consistency // Long Range Planning. — 2010. — Vol. 43. — No. 2. — Р. 227–246.
39. Doleski O. Integrated business model. Applying the St. Gallen management concept to business models. — Wiesbaden: Springer Gabler, 2015.
40. Dubosson-Torbay M., Osterwalder A., Pigneur Y. E-business model design, classification, and measurements // Thunderbird International Business Review. — 2002. — Vol. 44. — No. 1. — P. 5–23.
41. Foss N. J., Saebi T. Business Model Innovation: The Organizational Dimension. Oxford Scholarship Online: April 2015.
42. Foss N. J., Saebi T. Fifteen years of research on business model innovation: How far have we come, and where should we go? // Journal of Management. — 2017. — Vol. 43. — No. 1. — P. 200–227.
43. Hamel G. Leading the revolution. — Boston: Harvard Business School Press, 2000.
44. Hawkins R. The phantom of the marketplace: Searching for new e-commerce business models // Euro CPR 2002. Barcelona, March, 24–26, 2002.
Barcelona, March, 24–26, 2002.
45. Hedman J., Kalling T. The business model concept: Theoretical underpinnings and empirical illustrations // European Journal of Information Systems. — 2003. — Vol. 12. — P. 49–59.
46. Higgins J. M. Organization Policy and Strategic Management: Text and Cases. — Chicago: The Drydent Press, 1983.
47. Hofer C. W., Schendel D. Strategy Formulation: Analytical Concepts. — St. Paul, MN: West Publishing, 1978.
48. Hoskisson R. E., Hitt M. A., Wan W. P., Yiu D. Theory and Research in Strategic Management: Swings of the Pendulum // Journal of Management. — 1999. — Vol. 25. — No. 3. — Р. 417–456.
49. Johnson M., Christensen C., Kagermann H. Reinventing tour business model // Harvard Business Review. — 2008. — Vol. 86. — No. 12. — P. 50–59.
50. Keen P., Qureshi S. Organizational Transformation Through Business Models: A Framework for Business Model Design // System Sciences, HICSS’06. Proceedings of the 39th Annual Hawaii International Conference, 2006, 8: 206b–206b.
51. Lecoq X., Demil B., Warnier V. Le Business Model, un Outil d’Analyse Strate ́gique // L’Expansion Management Review. — 2006. — Vol. 123. — P. 50–59.
52. Magretta J. Why business models matter? // Harvard Business Review. — 2002. — Vol. 80. — No. 5. — P. 86–92.
53. Mahadevan B. Business models for Internet-based E-Commerce. An Anatomy // California Management Review. — 2000. — Vol. 42. — No. 4. — P. 55–69.
54. McGrath R.G. Business Models: A Discovery Driven Approach // Long Range Planning. — 2010. — Vol. 43. — P. 247–261.
55. Mintzberg H. 1994. The Rise and Fall of Strategic Planning. — N. Y.: Free press. P. 221–321.
56. Mintzberg H. Patterns in strategy formulation // Management Science. — 1978. — Vol. 24. — No. 9. — P. 934–948.
57. Morris M., Schindehutte M., Allen J. The entrepreneur’s business model: Toward a unified perspective // Journal of Business Research. — 2005. — Vol. 58. — P. 726–735.
58. Onetti A., Zucchella A., Jones M. V., McDougall-Covin P.P. Internationalization, innovation and entrepreneurship: Business models for new technology-based firms // Journal of Management and Governance. — 2012. — Vol. 16. — P. 337- 368.
V., McDougall-Covin P.P. Internationalization, innovation and entrepreneurship: Business models for new technology-based firms // Journal of Management and Governance. — 2012. — Vol. 16. — P. 337- 368.
59. Osterwalder A., Pigneur Y. Business model generation: a handbook for visionaries, game changers, and challengers. — New Jersey: Wiley, 2010.
60. Osterwalder A., Pigneur Y., Tucci C. Clarifying business models: Origins, present, and future of the concept // Communications of the Association for Information Systems. — 2005. — Vol. 16. — P. 1–25.
61. Pearce J.A., Robinson R.B. Jr. Strategic Management: Strategy Formulation and Implementation. 2d ed. — Homewood, Ill.: Richard D. Irwin, 1985.
62. Peric M., Durkin J., Vitezic V. The constructs of a business model redefined: A half- century journey // SAGE Open. — 2017. — Vol. 7. — No. 3. — P. 1–13.
63. Peters T. Liberation Management. — N. Y.: Knopf, 1992.
64. Porter M. E. What Is Strategy? // Harvard Business Review. — 1996. — Vol. 74. — No. 6. — P. 61–78.
— 1996. — Vol. 74. — No. 6. — P. 61–78.
65. Richardson J. The business model: an integrative framework for strategy execution // Strategic Change. — 2008. — Vol. 17. — P. 133–144.
66. Roome N., Louche C. Journeying toward business models for sustainability: A conceptual model found inside the black box of organizational transformation // Organization & Environment. — 2016. — Vol. 29. — P. 11–35.
67. Rumelt R.P. Diversification strategy and profitability // Strategic Management Journal. — 1982. — Vol. 3. — No. 4. — P. 359–369.
68. Runfola A., Rosati M., Guercini S. New business models in online hotel distribution: Emerging private sales versus leading IDS // Service Business. — 2013. — No. 7. — P. 183–205.
69. Schendel D.E., Hatten K.J. Business policy or strategic management: A broader view for an emerging discipline // Academy of Management Proceedings. — 1972. — No. 1. — P. 99–102.
70. Shafer S., Smith H., Linder J. The power of business models // Business Horizons. — 2005. — Vol. 48. — P. 199–207.
— 2005. — Vol. 48. — P. 199–207.
71. Solaimani S., Bouwman H. A framework for the alignment of business model and business processes // Business Process Management Journal. — 2012. — Vol. 18. — No. 4. — P. 655–679.
72. Stewart D., Zhao Q. Internet marketing, business models and public policy // Journal of Public Policy and Marketing. — 2000. — Vol. 19. — P. 287–296.
73. Taran Y., Boer H., Lindgren P. A Business Model Innovation Typology // Decision Sciences. — 2015. — Vol. 46. — No. 2. — P. 301–331.
74. Teece D. Business models, business strategy and innovation // Long Range Planning. — 2010. — Vol. 43. — P. 172–194.
75. Thompson A.A., Strickland A.J. Grafting & Implementing Strategy. — IRWIN Press, 1995.
76. Tikkanen H., Lamberg J.-A., Parvinen P., Kallunki J.-P. Managerial cognition, action and the business model of the firm // Management Decision. — 2005. — Vol. 43. — No. 6. — P. 789–809.
77. Timmers P. Business models for electronic markets // Electronic Markets. — 1998. — Vol. 8. — No. 2. — Р. 3–8.
— 1998. — Vol. 8. — No. 2. — Р. 3–8.
78. Wernerfelt B. A resource-based view of the firm // Strategic Management Journal. — 1984. — Vol. 2. — No. 2. — Р. 171–180.
79. Williamson O. E. Markets and Hierarchies. N. Y.: Free Press, 1975.
80. Wirtz B. Electronic Business. Wiesbaden: Gabler, 2000.
81. Wirtz B., Pistoia A., Ullrich S., Göttel V. Business models: Origin, development and future research perspectives // Long Range Planning. — 2016. — Vol. 49. — No. 1. — P. 36–54.
82. Zollo M., Minoja M., Coda V. Toward an integrated theory of strategy // Strategic Management Journal. — 2017. — Vol. 39. — P. 1753–1778.
83. Zott C., Amit R. The fit between product market strategy and business model: implications for firm performance // Strategic Management Journal. — 2008. — Vol. 29. — No. 1. — P. 1-26.
84. Zott C., Amit R., Massa L. The Business Model: Recent Developments and Future Research // Journal of Management. — 2011. — Vol. 37. — No. 4. — P. 1019–1042.
Стратегии эволюции — Scholarpedia
| Ханс-Георг Бейер (2007), Scholarpedia, 2 (8): 1965. | doi:10.4249/scholarpedia.1965 | редакция #193589 [ссылка/цитировать эту статью] |
Постпубликационная деятельность
Куратор: Ханс-Георг Бейер
Авторы:
0,29 —
Николаус Хансен
0,29 —
Ижикевич Евгений Михайлович
0,14 —
Роберт Вюнше
0,14 —
Бенджамин Броннер
Доктор Ханс-Георг Бейер, Форарльбергский университет прикладных наук
Стратегии эволюции (ЭС) являются подклассом вдохновленных природой
методы прямого поиска (и оптимизации), принадлежащие к классу
Эволюционные алгоритмы (ЭА), которые используют мутацию, рекомбинацию,
отбор, применяемый к популяции особей, содержащих
возможные решения, чтобы итеративно развиваться все лучше и лучше
решения. * = \mathrm{argopt}_{{\mathbf{y} \in \mathcal{Y}}} \, f(\mathbf{y}),
\]
функция \(f(\mathbf{y})\), которую необходимо оптимизировать, также упоминается
как целевая (или целевая) функция, может быть представлена в математическом
форму, с помощью моделирования или даже с точки зрения измерений, полученных из
реальные объекты. ES также может быть применен к набору целевых функций
в контексте многоцелевой оптимизации
(см. также Многокритериальные эволюционные алгоритмы и Многокритериальный поиск).
* = \mathrm{argopt}_{{\mathbf{y} \in \mathcal{Y}}} \, f(\mathbf{y}),
\]
функция \(f(\mathbf{y})\), которую необходимо оптимизировать, также упоминается
как целевая (или целевая) функция, может быть представлена в математическом
форму, с помощью моделирования или даже с точки зрения измерений, полученных из
реальные объекты. ES также может быть применен к набору целевых функций
в контексте многоцелевой оптимизации
(см. также Многокритериальные эволюционные алгоритмы и Многокритериальный поиск).
Содержимое
|
Канонические версии ES
Канонические версии ES обозначаются
\[
(\mu/\rho, \lambda)\mbox{-ES} \quad \mbox{and} \quad
(\mu/\rho + \lambda)\mbox{-ES},
\]
соответственно. Здесь \(\mu\) обозначает количество родителей,
\(\rho \leq \mu\) число смешивания (т. е. количество родителей
участвует в рождении потомства), и \(\лямбда\)
количество потомства. Родители детерминистически выбраны
(т. е. детерминированный отбор выживших) из
(много) набор потомков, обозначаемый как выбор запятой (\( \mu < \lambda \) должно выполняться), или как родители, так и потомство,
называется плюс-выбор .
Выбор основан на рейтинге пригодности людей.
\(F(\mathbf{y})\), взяв \(\mu \) лучших особей
(также называется усеченным выбором). В общем,
\[
\mbox{ES индивидуальный} \quad \mathbf{a} := (\mathbf{y}, \mathbf{s}, F(\mathbf{y}))
\]
содержит вектор параметров объекта \(\mathbf{y} \in \mathcal{Y}\) для оптимизации,
набор параметров стратегии \(\mathbf{s}\ ,\), необходимых особенно в
самоадаптирующиеся ЭС и наблюдаемая приспособленность человека \(F(\mathbf{y})\)
эквивалентна целевой функции \(f(\mathbf{y})\ ,\), т. е.
\(F(\mathbf{y}) \equiv f(\mathbf{y})\) в простейшем случае.
Здесь \(\mu\) обозначает количество родителей,
\(\rho \leq \mu\) число смешивания (т. е. количество родителей
участвует в рождении потомства), и \(\лямбда\)
количество потомства. Родители детерминистически выбраны
(т. е. детерминированный отбор выживших) из
(много) набор потомков, обозначаемый как выбор запятой (\( \mu < \lambda \) должно выполняться), или как родители, так и потомство,
называется плюс-выбор .
Выбор основан на рейтинге пригодности людей.
\(F(\mathbf{y})\), взяв \(\mu \) лучших особей
(также называется усеченным выбором). В общем,
\[
\mbox{ES индивидуальный} \quad \mathbf{a} := (\mathbf{y}, \mathbf{s}, F(\mathbf{y}))
\]
содержит вектор параметров объекта \(\mathbf{y} \in \mathcal{Y}\) для оптимизации,
набор параметров стратегии \(\mathbf{s}\ ,\), необходимых особенно в
самоадаптирующиеся ЭС и наблюдаемая приспособленность человека \(F(\mathbf{y})\)
эквивалентна целевой функции \(f(\mathbf{y})\ ,\), т. е.
\(F(\mathbf{y}) \equiv f(\mathbf{y})\) в простейшем случае. Различие между \(F(\mathbf{y})\) и \(f(\mathbf{y})\)
необходимо, так как \(F(\mathbf{y})\) может быть результатом локального
оператор поиска, который применяется к \(f(\mathbf{y})\)-функции
быть оптимизированным, или даже
может быть результатом другого ES (см. Мета-ES ниже).
Кроме того, наблюдаемое \(F(\mathbf{y})\) может быть результатом
зашумленный \(f(\mathbf{y})\)-процесс оценки.
Различие между \(F(\mathbf{y})\) и \(f(\mathbf{y})\)
необходимо, так как \(F(\mathbf{y})\) может быть результатом локального
оператор поиска, который применяется к \(f(\mathbf{y})\)-функции
быть оптимизированным, или даже
может быть результатом другого ES (см. Мета-ES ниже).
Кроме того, наблюдаемое \(F(\mathbf{y})\) может быть результатом
зашумленный \(f(\mathbf{y})\)-процесс оценки.
Концептуальный алгоритм \((\mu/\rho \; \stackrel{+}{,} \;\lambda)\)-ES приведен ниже:
\((\mu/\rho \; \stackrel{+}{,} \; \lambda)\)-Самоадаптация-Эволюция-Стратегия
- Инициализировать родительскую популяцию \(\mathbf{P}_\mu = \{ \mathbf{a}_1, \ldots, \mathbf{a}_{\mu} \}\ .\)
- Создание \(\lambda\) потомков \(\tilde{\mathbf{a}}\), формирующих популяцию потомков \(\tilde{\mathbf{P}}_\lambda = \{ \tilde{\mathbf{ a}}_1, \ldots, \tilde{\mathbf{a}}_\lambda\}\), где каждое потомство \(\tilde{\mathbf{a}}\) генерируется:
- Выбрать (случайно) \(\rho\) родителей из \(\mathbf{P}_\mu\) (если \(\rho = \mu\) вместо этого взять всех родительских особей).

- Рекомбинация \(\rho\) выбранных родителей \(\mathbf{a}\) для формирования рекомбинантной особи \(\mathbf{r}\ .\)
- Мутировать набор параметров стратегии \(\mathbf{s}\) рекомбинантного \(\mathbf{r}\ .\)
- Измените набор целевых параметров \(\mathbf{y}\) рекомбинантного \(\mathbf{r}\), используя набор параметров измененной стратегии для управления статистическими свойствами мутации параметров объекта.
- Выбрать (случайно) \(\rho\) родителей из \(\mathbf{P}_\mu\) (если \(\rho = \mu\) вместо этого взять всех родительских особей).
- Выберите новую родительскую популяцию (используя детерминированный выбор усечения) из
- популяция потомков \(\tilde{\mathbf{P}}_\lambda\) (обозначается как запятая -отбор, обычно обозначается как «\((\mu,\lambda)\)-отбор «), или же
- потомок \(\tilde{\mathbf{P}}_\lambda\) и родительская \(\mathbf{P}_\mu\) популяция (обозначается как плюс -отбор, обычно обозначается как «\((\mu + \lambda)\)-выбор»)
- Перейти к 2. до критерий завершения выполнен.
В зависимости от области поиска и целевой функции
\(f(\mathbf{y})\ ,\) рекомбинация и/или мутация
параметры стратегии могут встречаться или не встречаться в конкретных реализациях
алгоритм. Например, \((\mu/1 + \lambda)\)-ES,
или, что то же самое, \((\mu + \lambda)\)-ES не использует рекомбинацию.
Он рисует своих новых \(\mu\) родителей для следующего поколения
как от старых \(\mu\) родителей, так и от \(\lambda\)
потомство (полученное от этих родителей), взяв лучшее
\(\mu\) особи
(относительно наблюдаемого \(F(\mathbf{y})\)).
Например, \((\mu/1 + \lambda)\)-ES,
или, что то же самое, \((\mu + \lambda)\)-ES не использует рекомбинацию.
Он рисует своих новых \(\mu\) родителей для следующего поколения
как от старых \(\mu\) родителей, так и от \(\lambda\)
потомство (полученное от этих родителей), взяв лучшее
\(\mu\) особи
(относительно наблюдаемого \(F(\mathbf{y})\)).
Стратегии эволюции типа \((\mu/\rho + 1)\) также упоминаются
в as стационарные ЭС , т.е. стратегии без разрыва между поколениями:
Они производят только одно потомство в каждом поколении. После оценки своего
пригодности \(F(\mathbf{y})\ ,\) худший индивидуум удаляется из
Население. Стратегии этого типа особенно полезны на параллельных
компьютеры, когда время для расчета пригодности людей
непостоянный, что позволяет выполнять асинхронную параллельную обработку.
9{\ тау \ mathrm {N} _l (0,1)}, \\ [2 мм]
& \mathbf{y}_l \leftarrow \langle \mathbf{y} \rangle +
\sigma_l \mathbf{N}_l(\mathbf{0}, \mathbf{I}), \\[2 мм]
& F_l \leftarrow F(\mathbf{y}_l),
\end{случаи}
\qquad\qquad\mbox{(I)}
\]
представляющие шаги 2 и 3 концептуального
\((\mu/\rho \; \stackrel{+}{,} \; \lambda)\)-Самоадаптация-Эволюция-Стратегия
алгоритм (инициализация, цикл эволюции и условие завершения
не показаны). \(\mathrm{N}_l(0,1)\) и
\(\mathbf{N}_l(\mathbf{0}, \mathbf{I})\) обычно (0, 1)
распределенные случайные скаляры и векторы соответственно, реализующие
операция мутации для параметра стратегии \(\sigma\)
и \(n\)-мерный вектор параметров объекта
\(\mathbf{y}.\) Обе операции мутации применяются к
соответствующие рекомбинанты \(\langle \sigma \rangle\) и
\(\langle \mathbf{y} \rangle.\) Измененный параметр стратегии
\(\sigma_l\) контролирует силу параметра объекта
мутация (в этом примере \(\sigma_l\) — это просто
стандартное отклонение нормально распределенных случайных составляющих).
Эта мутация аддитивно применяется к рекомбинантному
\(\langle \mathbf{y} \rangle.\) Изменение силы мутации
\(\сигма\) согласно (I),
позволяет самонастройка силы мутации:
Поскольку \(\sigma_l\) человека контролирует генерацию
\(\mathbf{y}_l,\) индивидуума, выбирающего конкретный
индивидуум \(\mathbf{a}_l\) в соответствии с его пригодностью
\(F(\mathbf{y}_l)\) приводит к наследованию
соответствующее значение \(\sigma_l\).
\(\mathrm{N}_l(0,1)\) и
\(\mathbf{N}_l(\mathbf{0}, \mathbf{I})\) обычно (0, 1)
распределенные случайные скаляры и векторы соответственно, реализующие
операция мутации для параметра стратегии \(\sigma\)
и \(n\)-мерный вектор параметров объекта
\(\mathbf{y}.\) Обе операции мутации применяются к
соответствующие рекомбинанты \(\langle \sigma \rangle\) и
\(\langle \mathbf{y} \rangle.\) Измененный параметр стратегии
\(\sigma_l\) контролирует силу параметра объекта
мутация (в этом примере \(\sigma_l\) — это просто
стандартное отклонение нормально распределенных случайных составляющих).
Эта мутация аддитивно применяется к рекомбинантному
\(\langle \mathbf{y} \rangle.\) Изменение силы мутации
\(\сигма\) согласно (I),
позволяет самонастройка силы мутации:
Поскольку \(\sigma_l\) человека контролирует генерацию
\(\mathbf{y}_l,\) индивидуума, выбирающего конкретный
индивидуум \(\mathbf{a}_l\) в соответствии с его пригодностью
\(F(\mathbf{y}_l)\) приводит к наследованию
соответствующее значение \(\sigma_l\). {\mu} a_{m;\lambda},
\qquad\qquad\mbox{(II)}
\]
где «\(m;\lambda\)» обозначает \(m\)-й лучший
потомство особи (последнего поколения). Этот тип
рекомбинация называется глобальный промежуточный рекомбинации и обозначается нижним индексом \(I\), присоединенным к
число смешивания \(\rho\ .\) Кроме промежуточного
рекомбинация есть и другие типы, например. дискретная рекомбинация
где родительские компоненты передаются по координатам случайным образом
к рекомбинантному.
{\mu} a_{m;\lambda},
\qquad\qquad\mbox{(II)}
\]
где «\(m;\lambda\)» обозначает \(m\)-й лучший
потомство особи (последнего поколения). Этот тип
рекомбинация называется глобальный промежуточный рекомбинации и обозначается нижним индексом \(I\), присоединенным к
число смешивания \(\rho\ .\) Кроме промежуточного
рекомбинация есть и другие типы, например. дискретная рекомбинация
где родительские компоненты передаются по координатам случайным образом
к рекомбинантному.
Простые реализации \((\mu/\mu_I, \lambda)\)-\(\sigma\)-Самоадаптация-ES для Mathematica и Matlab/Octave можно найти здесь.
Варианты ES и принципов проектирования оператора
В то время как \((\mu/\mu_I,\lambda)\)-ES в уравнении. (я) использует
изотропно распределенные мутации для вектора параметров объекта
\(\mathbf{y}\ ,\) более продвинутые ES используют адаптация ковариационной матрицы (CMA) методы (CMA-ES), позволяющие
для коррелированных мутаций в пространствах поиска с действительными значениями. \gamma
\right]\mbox{-ES}
\]
с \(\lambda’\) субпопуляциями
\((\mu/\rho, \lambda)\)-ES работают
независимо в течение ряда поколений \(\gamma\)
(время изоляции).
Такие стратегии используются в смешанной структуре и параметрах.
оптимизационные задачи и для эволюционного изучения стратегии
параметры (например, размер популяции, параметры мутации)
внутренняя петля эволюции.
\gamma
\right]\mbox{-ES}
\]
с \(\lambda’\) субпопуляциями
\((\mu/\rho, \lambda)\)-ES работают
независимо в течение ряда поколений \(\gamma\)
(время изоляции).
Такие стратегии используются в смешанной структуре и параметрах.
оптимизационные задачи и для эволюционного изучения стратегии
параметры (например, размер популяции, параметры мутации)
внутренняя петля эволюции.
Производительность ЭС на конкретном классе задач зависит решающее значение для дизайна ES-операторов (мутация, рекомбинация, выбора) и от того, каким образом ES-операторы адаптировались в процессе эволюции (схемы адаптации, например, \(\sigma\)-самоадаптация, адаптация ковариационной матрицы, так далее.). В идеале они должны быть спроектированы таким образом. что они гарантируют эволюционируемость системы во всем весь процесс эволюции. Вот некоторые принципы и общие методические рекомендации:
- Отбор осуществляется путем усечения популяции аналогично тому, что делают селекционеры при разведении животных или растений.
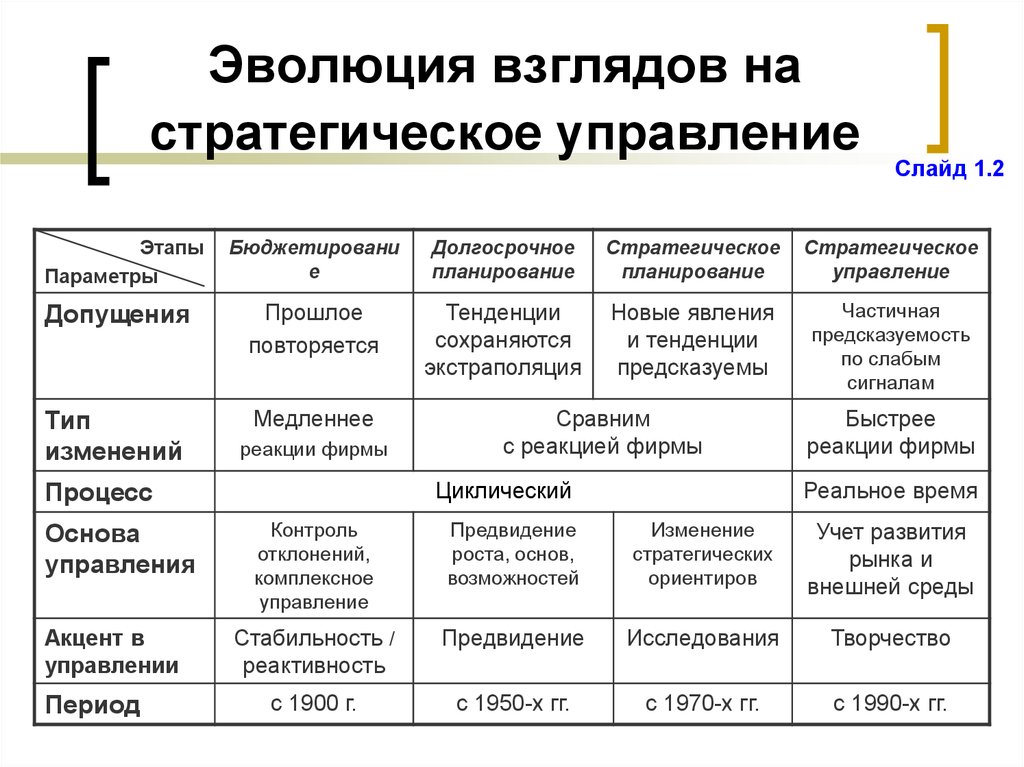
- Типичные коэффициенты усечения \(\mu/\lambda\) в стратегиях с запятой -выборка в непрерывных пространствах поиска находятся в диапазоне от 1/7 до 1/2.
- Использование плюс -отбора (своего рода элитарного отбора) в сочетании с операторами вариации, позволяющими достичь любой точки в конечных дискретных пространствах поиска за конечное время, гарантирует стохастическую сходимость для глобального оптимизатора. Однако, поскольку это результат, справедливый только для бесконечного времени работы, нельзя делать общие выводы относительно поведения ES за конечное время.
- Использование плюс — выбор рекомендуется для задач комбинаторной оптимизации.
- Эволюция ЭС обычно моделируется на уровне фенотипа . Задача, которую нужно оптимизировать, обычно представляется в ее естественном представлении проблемы, пытаясь соблюсти принцип сильной причинности. Это означает, что операторы вариации (мутации и рекомбинации) должны выполнять шаги поиска таким образом, чтобы небольшие шаги поиска приводили к небольшим изменениям пригодности, и наоборот.
 n\) (целочисленных) пространствах поиска.
n\) (целочисленных) пространствах поиска. - Рекомбинация применяется везде, где это возможно и полезно. Он использует \(\rho=2\) или более родительских особей для создания одного рекомбинанта (случай \(\rho > 2\) называется мультирекомбинацией ). Основная цель рекомбинации — сохранение общих компонентов родителей, т. е. передача (полезных) сходств следующему поколению и ослабление действия вредоносных компонентов родительских генов (эффект генетической репарации).
Обратите внимание, что не всегда возможно соблюдать все принципы проектирования в
конкретные приложения. Нарушение некоторых из этих принципов
не обязательно приводит к неэффективным стратегиям.
9* = \ mathrm {argopt} _ {\ mathbf {y}} f (\ mathbf {y}) \)
где \(\mathbf{y}\) — вектор, описывающий перестановку
\(n\) компонентов.
Например, \(\mathbf{y} = (1, 3, 9, 2, \ldots)\) описывает порядок
компонентов, например, порядок номеров городов, которые посещает продавец
последовательно (задача коммивояжера) или порядок работы
в задаче планирования рабочего места таким образом, что общая стоимость
\(е(\mathbf{у})\)
минимальны. В ЭС эта оптимизационная задача обычно представлена в ее естественное представление задачи , т. е. операторы вариации действуют
непосредственно в порядке \(\mathbf{y}\ .\) Индивидуум определяется как
\(\mathbf{a} = (\mathbf{y}, F(\mathbf{y}))\ .\)
ЭС генерирует потомство \(\лямбда\) в соответствии с
\[
\для всех l=1, \ldots, \lambda : \;\;
\begin{случаи}
& m \leftarrow \mbox{rand}\{1, \mu\}, \\[2 мм]
& \mathbf{y}_l \leftarrow \mbox{PerMutate}( \mathbf{y}_{m; \, \mu+\lambda}), \\[2mm]
& F_l \leftarrow F(\mathbf{y}_l)
\end{случаи}
\]
представляющие шаги 2 и 3 концептуального алгоритма ES. ES выбирает
случайным образом родитель из набора \(\mu\) лучших индивидуумов из обоих
родители и потомство последнего поколения (обозначены
\(\mathbf{y}_{m; \, \mu+\lambda}\) обозначение). Затем этот родитель
мутировал случайной перестановкой. Простые операторы перестановки
показан на рисунке 1.
В ЭС эта оптимизационная задача обычно представлена в ее естественное представление задачи , т. е. операторы вариации действуют
непосредственно в порядке \(\mathbf{y}\ .\) Индивидуум определяется как
\(\mathbf{a} = (\mathbf{y}, F(\mathbf{y}))\ .\)
ЭС генерирует потомство \(\лямбда\) в соответствии с
\[
\для всех l=1, \ldots, \lambda : \;\;
\begin{случаи}
& m \leftarrow \mbox{rand}\{1, \mu\}, \\[2 мм]
& \mathbf{y}_l \leftarrow \mbox{PerMutate}( \mathbf{y}_{m; \, \mu+\lambda}), \\[2mm]
& F_l \leftarrow F(\mathbf{y}_l)
\end{случаи}
\]
представляющие шаги 2 и 3 концептуального алгоритма ES. ES выбирает
случайным образом родитель из набора \(\mu\) лучших индивидуумов из обоих
родители и потомство последнего поколения (обозначены
\(\mathbf{y}_{m; \, \mu+\lambda}\) обозначение). Затем этот родитель
мутировал случайной перестановкой. Простые операторы перестановки
показан на рисунке 1.
Рисунок 1: Четыре оператора перестановки: слева направо и сверху вниз: инверсия, вставка, 2-обмен и сдвиг.
Представляют собой элементарные шаги перемещения, определяющие определенный поиск
окрестности (количество состояний, до которых можно добраться за один шаг).
В отличие от мутаций в непрерывных пространствах поиска, всегда существует
минимальный шаг поиска (представляющий наименьшую возможную мутацию).
Производительность различных операторов перестановки зависит от
оптимизационная задача, которую необходимо решить. Попытка обеспечить 9п\) пространства поиска. CMA-ES имеет
предложены А. Гавельчиком, Н. Хансеном и А. Остермайером в
середина 1990-х. Его принципиальное отличие от
\((\mu/\mu_I, \lambda)\)-\(\sigma\)-Самоадаптация-ES
Примером является форма распределения мутаций, которая генерируется
в соответствии с ковариационной матрицей \(\mathbf{C}\), которая адаптировал в ходе эволюции. Таким образом, мутации могут адаптироваться к местным условиям.
форма фитнес-ландшафта и приближение к оптимуму могут быть
значительно возросла. Он использует специальную статистику, накопленную за
поколений для управления эндогенными параметрами, специфичными для стратегии
(ковариационная матрица \(\mathbf{C}\) и глобальный шаг
размер \(\сигма\)). Это в отличие от (мутативного)
\(\sigma\)-подход к самоадаптации рассматривался ранее.
Упрощенный (но хорошо работающий) экземпляр дочернего обновления
формулы стратегии \((\mu/\mu_I, \lambda)\)-CMA для
небольшие размеры популяции \(\lambda\) (небольшие, по сравнению с
размерность пространства поиска \(n\)) читает
Это в отличие от (мутативного)
\(\sigma\)-подход к самоадаптации рассматривался ранее.
Упрощенный (но хорошо работающий) экземпляр дочернего обновления
формулы стратегии \((\mu/\mu_I, \lambda)\)-CMA для
небольшие размеры популяции \(\lambda\) (небольшие, по сравнению с
размерность пространства поиска \(n\)) читает
\((\mu/\mu_I, \лямбда)\)-CMA-ES
\[\mbox{(L1):} \quad
\для всех l=1, \ldots, \lambda : \;\;
\begin{случаи}
& \mathbf{w}_l
\leftarrow \sigma \sqrt{\mathbf{C}} \,
\mathbf{N}_l(\mathbf{0}, \mathbf{1}),\\[2 мм]
& \mathbf{y}_l \leftarrow \mathbf{y} + \mathbf{w}_l, \\[2мм]
& F_l \leftarrow F(\mathbf{y}_l),
\end{случаи}
\]
\[\mbox{(L2):} \quad
\mathbf{y} \leftarrow \mathbf{y} + \langle \mathbf{w} \rangle,
\]
\[\mbox{(L3):} \quad
\mathbf{s} \leftarrow \left(1-\frac{1}{\tau}\right)\mathbf{s}
+ \sqrt{\frac{\mu}{\tau} \left(2-\frac{1}{\tau}\right)} \,
\ frac {\ langle \ mathbf {w} \ rangle {\ sigma},
\]
\[\mbox{(L4):} \quad
\mathbf{C} \leftarrow
\left(1-\frac{1}{\tau_{\mathrm{c}}}\right)\mathbf{C}
+ \frac{1}{\tau_{\mathrm{c}}} \mathbf{s} \mathbf{s}^T,
\]
\[\mbox{(L5):} \quad
\mathbf{s}_\сигма
\leftarrow \left(1-\frac{1}{\tau_\sigma}\right) \mathbf{s}_\sigma
+ \ sqrt {\ frac {\ mu} {\ tau_ \ sigma}
\left(2-\frac{1}{\tau_\sigma}\right)} \,
\langle \mathbf{N}(\mathbf{0}, \mathbf{1}) \rangle ,
\]
\[\mbox{(L6):} \quad
\ сигма \ стрелка влево \ сигма \ exp \ влево [
\ гидроразрыва {\ | \mathbf{s}_{\sigma} \|^2 — n}
{2 н \sqrt{п} }
\Правильно]. 2\ .\)
Остальные (L5) и (L6) используются для управления размером глобального шага.
\(\sigma\) с использованием кумулятивной адаптации размера шага (CSA)
метод с постоянной времени \(\tau_\sigma = \sqrt{n}\)
(\(\mathbf{s}_\sigma = \mathbf{0}\,\) изначально выбрано).
Рекомбинантный \(\langle \mathbf{N}(\mathbf{0}, \mathbf{1}) \rangle\)
рассчитывается с использованием уравнения (II).
9Т.
\]
Чтобы в полной мере воспользоваться этим обновлением, константы времени
\(\тау\,\) \(\тау_{\mathrm{c}}\,\) и
\(\tau_\sigma\) должны быть выбраны соответственно
(см. Хансен и др., 2003).
2\ .\)
Остальные (L5) и (L6) используются для управления размером глобального шага.
\(\sigma\) с использованием кумулятивной адаптации размера шага (CSA)
метод с постоянной времени \(\tau_\sigma = \sqrt{n}\)
(\(\mathbf{s}_\sigma = \mathbf{0}\,\) изначально выбрано).
Рекомбинантный \(\langle \mathbf{N}(\mathbf{0}, \mathbf{1}) \rangle\)
рассчитывается с использованием уравнения (II).
9Т.
\]
Чтобы в полной мере воспользоваться этим обновлением, константы времени
\(\тау\,\) \(\тау_{\mathrm{c}}\,\) и
\(\tau_\sigma\) должны быть выбраны соответственно
(см. Хансен и др., 2003).
Ссылки
- Бейер, Х.-Г. и Швефель, Х.-П. (2002). Стратегии эволюции: всестороннее введение. В Natural Computing, 1(1):3-52.
- Бейер, Х.-Г. (2001). Теория эволюционных стратегий. Серия «Естественные вычисления». Спрингер, Берлин, 2001 г.
- Хансен, Н. и Остермайер, А. (2001). Полностью дерандомизированная самоадаптация в стратегиях эволюции. В Evolutionary Computation, 9(1):159-195.

- Хансен, Н. и Мюллер, С.Д. и Комуцакос, П. (2003). Снижение временной сложности стратегии дерандомизированной эволюции с адаптацией ковариационной матрицы (CMA-ES). В Эволюционные вычисления, 11(1):1-18.
- Рехенберг, И. (1994). Эволюционная стратегия ’94. Frommann-Holzboog Verlag, Штутгарт (на немецком языке).
- Швефель, Х.-П. (1995). Эволюция и поиск оптимума. Уайли, Нью-Йорк, штат Нью-Йорк.
Внутренние ссылки
- Ян А. Сандерс (2006) Усреднение. Scholarpedia, 1 (11): 1760.
- Томаш Даунарович (2007) Энтропия. Scholarpedia, 2(11):3901.
- Роб Шрайбер (2007) MATLAB. Scholarpedia, 2(7):2929.
- Фрэнк Хоппенстедт (2006 г.) Модель «хищник-жертва». Scholarpedia, 1 (10): 1563.
Внешние ссылки
- Веб-сайт Ханса-Георга Бейера
- Эволюционные_алгоритмы — термины и определения
- Веб-сайт, посвященный стратегии развития, кафедры бионики Берлинского технического университета
- Веб-сайт Николауса Хансена с материалами, связанными с CMA-ES
- Х.
 n \to \mathbb{R}$, даже если вы не знаете точную аналитическую форму $f( x)$ и поэтому не может вычислять градиенты или матрицу Гессе. Примеры методов оптимизации черного ящика включают имитация отжига, восхождение на холм и метод Нелдера-Мида. 9н$.
n \to \mathbb{R}$, даже если вы не знаете точную аналитическую форму $f( x)$ и поэтому не может вычислять градиенты или матрицу Гессе. Примеры методов оптимизации черного ящика включают имитация отжига, восхождение на холм и метод Нелдера-Мида. 9н$.Эволюционные алгоритмы относятся к подразделу алгоритмов оптимизации на основе популяции, вдохновленных естественным отбором . Естественный отбор считает, что люди с чертами, полезными для их выживания, могут жить в поколениях и передавать хорошие характеристики следующему поколению. Эволюция происходит постепенно в процессе отбора, и популяция становится лучше приспособленной к окружающей среде.
Рис. 1. Как работает естественный отбор. (Источник изображения: Академия Хана: Дарвин, эволюция и естественный отбор)Эволюционные алгоритмы можно обобщить в следующем формате как общее решение по оптимизации:
Допустим, мы хотим оптимизировать функцию $f(x)$, но не можем напрямую вычислять градиенты. Но мы по-прежнему можем вычислить $f(x)$ при любом $x$, и результат будет детерминированным.
903:30 Мы верим в то, что распределение вероятностей по $x$ является хорошим решением для оптимизации $f(x)$, это $p_\theta(x)$, параметризуемое $\theta$. Цель состоит в том, чтобы найти оптимальную конфигурацию $\theta$.
Мы верим в то, что распределение вероятностей по $x$ является хорошим решением для оптимизации $f(x)$, это $p_\theta(x)$, параметризуемое $\theta$. Цель состоит в том, чтобы найти оптимальную конфигурацию $\theta$.Здесь задан фиксированный формат распределения (т. е. гауссово), параметр $\theta$ содержит информацию о лучших решениях и итеративно обновляется из поколения в поколение.
Начиная с начального значения $\theta$, мы можем непрерывно обновлять $\theta$, повторяя три шага следующим образом:
- Сгенерировать совокупность образцов $D = \{(x_i, f(x_i)\} $ где $x_i \sim p_\theta(x)$.
- Оцените «пригодность» образцов в $D$. 92 C) \sim \mu + \sigma \mathcal{N}(0, C) $$
- Она всегда диагонализируема. 9{(т)}$
путь оценки для $C$ в поколении (t) $\alpha_\mu$ скорость обучения для обновления $\mu$ $\альфа_\сигма$ скорость обучения для $p_\sigma$ $d_\sigma$ Коэффициент демпфирования для обновления $\sigma$ $\alpha_{cp}$ Скорость обученияза $p_c$ $\alpha_{c\lambda}$ скорость обучения для обновления $C$ rank-min(λ, n) 9{(j)}, j=1, \dots, t$. Сравнивая эту длину пути с ее ожидаемой длиной при случайном выборе (это означает, что отдельные шаги не коррелированы), мы можем соответствующим образом скорректировать $\sigma$ (см. рис. 2). Рис. 2. Три сценария того, как отдельные шаги соотносятся по-разному, и их влияние на обновление размера шага.  (Источник изображения: дополнительные аннотации к рис. 5 в учебном документе CMA-ES)
(Источник изображения: дополнительные аннотации к рис. 5 в учебном документе CMA-ES)Каждый раз, когда путь эволюции обновляется средним значением шага перемещения $y_i$ в том же поколении. 9\Топ $$
Приведенная выше оценка надежна только в том случае, если выбранная совокупность достаточно велика. Тем не менее, мы хотим запустить 90 323 быстрых 90 324 итераций с 90 323 небольшими 90 324 популяциями выборок в каждом поколении. Вот почему CMA-ES изобрел более надежный, но и более сложный способ обновления $C$. Он включает два независимых маршрута:
- Rank-min(λ, n) update : использует историю $\{C_\lambda\}$, каждый оценивается с нуля в одном поколении. 9\top$ теряет информацию о знаке. Подобно тому, как мы настраиваем размер шага $\sigma$, для отслеживания информации о знаке используется эволюционный путь $p_c$, построенный таким образом, что $p_c$ является сопряженным, $\sim \mathcal{N}(0 , C)$ как до, так и после нового поколения.
- NES применяет формирование пригодности на основе рангов , то есть использует ранг при монотонно возрастающих значениях пригодности вместо прямого использования $f(x)$.
 Или это может быть функция ранга («функция полезности»), которая считается свободным параметром НЭС.
Или это может быть функция ранга («функция полезности»), которая считается свободным параметром НЭС. - NES использует выборку адаптации для настройки гиперпараметров во время выполнения. При замене $\theta\на \theta’$ выборки, взятые из $p_\theta$, сравниваются с выборками из $p_{\theta’}$ с помощью [U-критерия Манна-Уитни(https://en.wikipedia. org/wiki/Манн%E2%80%93Whitney_U_test)]; если показывает положительный или отрицательный знак, целевой гиперпараметр уменьшается или увеличивается на константу умножения. Обратите внимание, что к показателю выборки $x’_i \sim p_{\theta’}(x)$ применяются весовые коэффициенты важности выборки $w_i’ = p_\theta(x) / p_{\theta’}(x)$.
- Средний участник совокупности CEM $\pi_\mu$ инициализируется сетью случайных участников.
- Также инициализирована критическая сеть $Q$, которая будет обновлена DDPG/TD3.
- Повторять до счастливого:
- а. Выберите группу актеров $\sim \mathcal{N}(\pi_\mu, \Sigma)$.
- б. Оценивается половина населения. Их показатели физической подготовки используются в качестве совокупной награды $R$ и добавляются в буфер воспроизведения.
- с. Другая половина обновляется вместе с критиком.
- д. Новые значения $\pi_mu$ и $\Sigma$ рассчитываются с использованием наиболее эффективных элитных выборок. CMA-ES также можно использовать для обновления параметров.
-
explore(): Если веса модели перезаписываются, шагexploreвозмущает гиперпараметры случайным шумом.
Мы можем рассматривать $p_c$ как еще один способ вычисления $\text{avg}_i(y_i)$ (обратите внимание, что как $\sim \mathcal{N}(0, C)$), когда используется вся история, так и информация о знаке сохраняется.
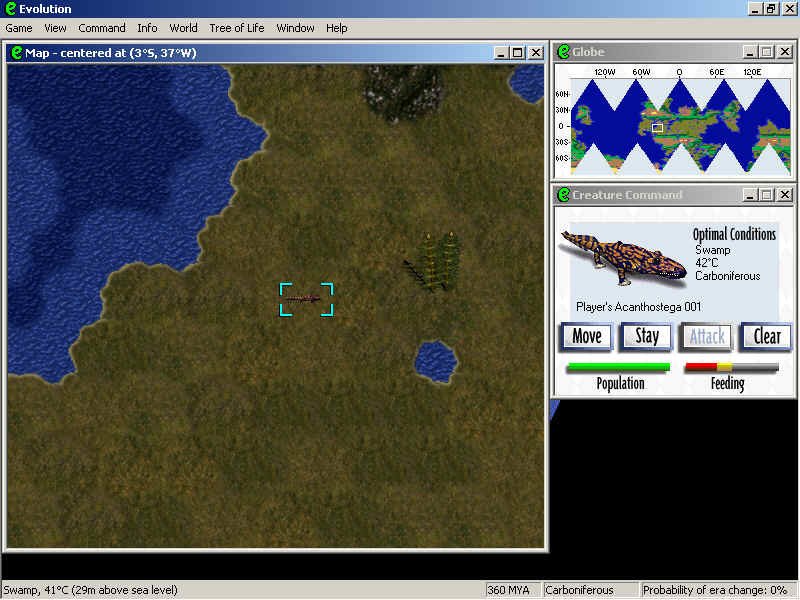 {(t)}} \sim \mathcal{ N}(0, C)$ в последнем разделе, 9\top}_\textrm{обновление минимального ранга (лямбда, n)}
$$
{(t)}} \sim \mathcal{ N}(0, C)$ в последнем разделе, 9\top}_\textrm{обновление минимального ранга (лямбда, n)}
$$Во всех приведенных выше примерах считается, что каждая элитная выборка дает одинаковое количество весов, $1/\lambda$. Этот процесс можно легко распространить на случай, когда выбранным образцам присваиваются разные веса, $w_1, \dots, w_\lambda$, в соответствии с их характеристиками. Более подробно смотрите в учебнике.
Рис. 3. Иллюстрация того, как CMA-ES работает с задачей оптимизации 2D (чем светлее цвет, тем лучше). Черные точки – образцы в одном поколении. Первоначально выборки более разбросаны, но когда модель с большей уверенностью находит хорошее решение на поздней стадии, выборки становятся очень сконцентрированными над глобальным оптимумом. (Источник изображения: Wikipedia CMA-ES)Natural Evolution Strategies ( NES ; Wierstra, et al, 2008) оптимизирует распределение параметров поиска и перемещает распределение в направлении высокой приспособленности, обозначенной естественным градиентом .

Естественные градиенты
Если задана целевая функция $\mathcal{J}(\theta)$, параметризованная $\theta$, допустим, наша цель состоит в том, чтобы найти оптимальную $\theta$ для максимизации значения целевой функции. Плоский градиент находит самое крутое направление в пределах небольшого евклидова расстояния от текущего $\theta$; ограничение расстояния применяется к пространству параметров. Другими словами, мы вычисляем простой градиент относительно небольшого изменения абсолютного значения $\theta$. Оптимальный шаг: 9{*} = \operatorname*{argmax}_{\|d\| = \epsilon} \mathcal{J}(\theta + d)\text{, где}\epsilon \to 0 $$
Иными словами, естественный градиент работает с пространством распределения вероятностей, параметризованным $\theta$, $p_\theta(x)$ (называемым «распределением поиска» в документе NES). Он ищет самое крутое направление в пределах небольшого шага в пространстве распределения, где расстояние измеряется дивергенцией KL. С этим ограничением мы гарантируем, что каждое обновление движется по распределительному коллектору с постоянной скоростью, не замедляясь из-за его кривизны.
 2 _ \ тета \ log p _ {\ тета} (х)] d &
\end{выровнено}
$$
2 _ \ тета \ log p _ {\ тета} (х)] d &
\end{выровнено}
$$где
$$ \begin{выровнено} \mathbb{E}_x [\nabla_\theta \log p_{\theta}] d &= \int_{x\sim p_\theta} p_\theta(x) \nabla_\theta \log p_\theta(x) & \\ &= \int_{x\sim p_\theta} p_\theta(x) \frac{1}{p_\theta(x)} \nabla_\theta p_\theta(x) & \\ &= \nabla_\theta \Big( \int_{x} p_\theta(x) \Big) & \scriptstyle{\textrm{; обратите внимание, что }p_\theta(x)\textrm{ является распределением вероятностей.}} \\ &= \набла_\тета (1) = 0 \end{выровнено} $$
Наконец имеем 9{-1}$.
Рис. 4. Образцы естественного градиента (черные сплошные стрелки) справа представляют собой образцы простого градиента (черные сплошные стрелки) слева, умноженные на обратную их ковариацию. Таким образом, направление градиента с высокой неопределенностью (на которое указывает высокая ковариация с другими выборками) наказывается небольшим весом. Таким образом, агрегированный естественный градиент (красная пунктирная стрелка) заслуживает большего доверия, чем естественный градиент (зеленая сплошная стрелка). (Источник изображения: дополнительные аннотации к рис. 2 в документе NES)
(Источник изображения: дополнительные аннотации к рис. 2 в документе NES)Алгоритм NES
Пригодность, связанная с одной выборкой, помечается как $f(x)$, а распределение поиска по $x$ параметризуется $\theta$. Ожидается, что NES оптимизирует параметр $\theta$ для достижения максимальной ожидаемой пригодности:
$$ \mathcal{J}(\theta) = \mathbb{E}_{x\sim p_\theta(x)} [f(x)] = \int_x f(x) p_\theta(x) dx $$
Используя тот же прием логарифмического правдоподобия в REINFORCE:
$$ \begin{выровнено} \nabla_\theta\mathcal{J}(\theta) &= \nabla_\theta \int_x f(x) p_\theta(x) dx \\ &= \int_x f(x) \frac{p_\theta(x)}{p_\theta(x)}\nabla_\theta p_\theta(x) dx \\ & = \int_x f(x) p_\theta(x) \nabla_\theta \log p_\theta(x) dx \\ & = \mathbb{E}_{x \sim p_\theta} [f(x) \nabla_\theta \log p_\theta(x)] \end{выровнено} $$
Помимо естественных градиентов, NES использует несколько важных эвристик, чтобы сделать алгоритм более надежным.
OpenAI ES для RL
Концепцию использования эволюционных алгоритмов в обучении с подкреплением можно проследить давно, но она ограничена только табличным RL из-за вычислительных ограничений.
Вдохновленные NES, исследователи OpenAI (Salimans, et al. 2017) предложили использовать NES в качестве безградиентного оптимизатора черного ящика для поиска оптимальных параметров политики $\theta$, которые максимизируют функцию возврата $F(\theta)$ .
 2 I$, 9\top\epsilon\big) \nabla_\theta \big(\frac{\theta — \hat{\theta}}{\sigma}\big) F(\hat{\theta} + \sigma\epsilon)] & \\
&= \mathbb{E}_{\epsilon\sim\mathcal{N}(0, I)} [ (-\epsilon) (\frac{1}{\sigma}) F(\hat{\theta} + \сигма\эпсилон) ] & \\
& = \ frac {1} {\ sigma} \ mathbb {E} _ {\ epsilon \ sim \ mathcal {N} (0, I)} [ \ epsilon F (\ hat {\ theta} + \ sigma \ epsilon) ] & \scriptstyle{\text{; отрицательный знак может быть поглощен.}}
\end{выровнено}
$$
2 I$, 9\top\epsilon\big) \nabla_\theta \big(\frac{\theta — \hat{\theta}}{\sigma}\big) F(\hat{\theta} + \sigma\epsilon)] & \\
&= \mathbb{E}_{\epsilon\sim\mathcal{N}(0, I)} [ (-\epsilon) (\frac{1}{\sigma}) F(\hat{\theta} + \сигма\эпсилон) ] & \\
& = \ frac {1} {\ sigma} \ mathbb {E} _ {\ epsilon \ sim \ mathcal {N} (0, I)} [ \ epsilon F (\ hat {\ theta} + \ sigma \ epsilon) ] & \scriptstyle{\text{; отрицательный знак может быть поглощен.}}
\end{выровнено}
$$В одном поколении мы можем выбрать множество $epsilon_i, i=1,\dots,n$ и оценить пригодность параллельно . Прекрасная конструкция заключается в том, что нет необходимости совместно использовать большие параметры модели. Только путем передачи случайных начальных значений между рабочими узлами достаточно, чтобы мастер-узел выполнил обновление параметров. Позже этот подход был расширен для адаптивного изучения функции потерь; см. мой предыдущий пост об эволюционном градиенте политики.
Рис. 5. Алгоритм обучения политики RL с использованием эволюционных стратегий. (Источник изображения: документ ES-for-RL)
(Источник изображения: документ ES-for-RL)Чтобы повысить производительность, OpenAI ES использует виртуальную пакетную нормализацию (BN с фиксированным мини-пакетом, используемым для расчета статистики), зеркальную выборку (выборку пары $(-\epsilon , \epsilon)$ для оценки) и формирование пригодности.
Исследование с помощью ES
Исследование (по сравнению с эксплуатацией) — важная тема в RL. Направление оптимизации в приведенном выше алгоритме ES извлекается только из совокупного дохода $F(\theta)$. Без явного исследования агент может попасть в ловушку локального оптимума.
Novelty-Search ES ( NS-ES ; Conti et al, 2018) поощряет исследование, обновляя параметр в направлении, максимальном количестве баллов новизны . Оценка новизны зависит от функции характеристики поведения в предметной области $b(\pi_\theta)$. Выбор $b(\pi_\theta)$ зависит от задачи и кажется немного произвольным; например, в задаче на передвижение гуманоида в статье $b(\pi_\theta)$ является конечным $(x,y)$ местоположением агента.
Рис. 6. (Слева) Окружающая среда Гуманоидная локомоция с трехсторонней стеной, которая играет роль обманчивой ловушки для создания локального оптимума. (Справа) Эксперименты сравнивают базовый уровень ES и другие варианты, которые стимулируют исследования. (Источник изображения: документ NS-ES) { (t)}_m + \epsilon_i, \mathcal{A}) \text{ где }\epsilon_i \sim \mathcal{N}(0, I)
\end{выровнено}
$$ 9{(t)}_m + \epsilon_i)\big)
$$
{ (t)}_m + \epsilon_i, \mathcal{A}) \text{ где }\epsilon_i \sim \mathcal{N}(0, I)
\end{выровнено}
$$ 9{(t)}_m + \epsilon_i)\big)
$$CEM-RL
Рис. 7. Архитектуры алгоритмов (a) CEM-RL и (b) ERL (Источник изображения: документ CEM-RL)Метод CEM-RL (Pourchot & Sigaud, 2019) сочетает метод перекрестной энтропии (CEM) с DDPG или TD3. CEM здесь работает почти так же, как описанная выше простая гауссовская ES, и поэтому ту же функцию можно заменить с помощью CMA-ES. CEM-RL построен на базе Эволюционное обучение с подкреплением ( ERL ; Khadka & Tumer, 2018), в котором стандартный алгоритм EA выбирает и развивает популяцию участников, а опыт развертывания, полученный в процессе, затем добавляется в буфер ответов для обучения как RL-актера, так и RL-критик сетей.
Рабочий процесс:
(Этот раздел не посвящен стратегиям эволюции, но тем не менее является интересным и актуальным чтением.)
Эволюционные алгоритмы применялись во многих задачах глубокого обучения.
 POET (Wang et al, 2019) — это фреймворк, основанный на EA и пытающийся генерировать множество различных задач, пока решаются сами проблемы. POET был представлен в моем последнем посте на мета-RL. Еще одним примером является эволюционное обучение с подкреплением (ERL); См. рис. 7 (б).
POET (Wang et al, 2019) — это фреймворк, основанный на EA и пытающийся генерировать множество различных задач, пока решаются сами проблемы. POET был представлен в моем последнем посте на мета-RL. Еще одним примером является эволюционное обучение с подкреплением (ERL); См. рис. 7 (б).Ниже я хотел бы более подробно представить два приложения: Обучение населения (PBT) и Весонезависимые нейронные сети (WANN) .
Настройка гиперпараметров: PBT
Рис. 8. Парадигмы сравнения различных способов настройки гиперпараметров. (Источник изображения: документ PBT)Population-Based Training (Jaderberg, et al, 2017), сокращение от PBT применяет EA для решения проблемы настройки гиперпараметров. Он совместно обучает совокупность моделей и соответствующих гиперпараметров для достижения оптимальной производительности.
PBT начинается с набора случайных кандидатов, каждый из которых содержит пару инициализационных весов модели и гиперпараметров, $\{(\theta_i, h_i)\mid i=1, \dots, N\}$.
 Каждый образец обучается параллельно и периодически асинхронно оценивает собственную производительность. Всякий раз, когда участник считает себя готовым (т. е. после выполнения достаточного количества шагов обновления градиента или когда производительность достаточно высока), у него есть шанс обновиться путем сравнения со всей популяцией:0807 : Когда эта модель не работает, гири можно заменить на более производительную модель.
Каждый образец обучается параллельно и периодически асинхронно оценивает собственную производительность. Всякий раз, когда участник считает себя готовым (т. е. после выполнения достаточного количества шагов обновления градиента или когда производительность достаточно высока), у него есть шанс обновиться путем сравнения со всей популяцией:0807 : Когда эта модель не работает, гири можно заменить на более производительную модель.В этом процессе только многообещающие пары моделей и гиперпараметров могут выжить и продолжать развиваться, обеспечивая более эффективное использование вычислительных ресурсов.
Рис. 9. Алгоритм популяционного обучения. (Источник изображения: бумага PBT)Оптимизация топологии сети: WANN
Нейронные сети , не зависящие от веса (сокращение от WANN ; Gaier & Ha 2019) экспериментируют с поиском наименьших сетевых топологий, которые могут обеспечить оптимальную производительность без обучения весов сети.
 Не рассматривая наилучшую конфигурацию сетевых весов, WANN уделяет гораздо больше внимания самой архитектуре, что отличает ее от NAS. WANN сильно вдохновлен классическим генетическим алгоритмом для развития сетевых топологий, называемым NEAT («Нейроэволюция увеличивающих топологий»; Stanley & Miikkulainen 2002).
Не рассматривая наилучшую конфигурацию сетевых весов, WANN уделяет гораздо больше внимания самой архитектуре, что отличает ее от NAS. WANN сильно вдохновлен классическим генетическим алгоритмом для развития сетевых топологий, называемым NEAT («Нейроэволюция увеличивающих топологий»; Stanley & Miikkulainen 2002).Рабочий процесс WANN выглядит почти так же, как стандартный GA:
- Инициализация: создание совокупности минимальных сетей.
- Оценка: тест с диапазоном общих значений веса.
- Ранг и выбор: Ранг по производительности и сложности.
- Мутация: создайте новую популяцию, меняя лучшие сети.
На этапе «оценки» все веса сети устанавливаются одинаковыми. Таким образом, WANN фактически ищет сеть, которая может быть описана с минимальной длиной описания. На этапе «выбор» рассматривается как подключение к сети, так и производительность модели.
Рис. 11. Производительность обнаруженных сетевых топологий WANN при выполнении различных задач RL сравнивается с базовыми сетями FF, обычно используемыми в литературе. «Настроенный общий вес» требует настройки только одного значения веса. (Источник изображения: бумага WANN)
Как показано на рис. 11, результаты WANN оцениваются как со случайными весами, так и с общими весами (один вес). Интересно, что даже при принудительном распределении веса для всех весов и настройке этого единственного параметра WANN может обнаруживать топологии, которые обеспечивают нетривиальную хорошую производительность.
Цитируется как:
@article{weng2019ES, title = "Стратегии развития", автор = "Венг, Лилиан", журнал = "lilianweng.github.io", год = "2019", url = "https://lilianweng.github.io/posts/2019-09-05-эволюция-стратегии/" }[1] Николаус Хансен. «Стратегия развития CMA: Учебное пособие», препринт arXiv arXiv: 1604.00772 (2016 г.).
[2] Марк Туссен.
 Слайды: «Введение в оптимизацию»
Слайды: «Введение в оптимизацию»[3] Дэвид Ха. «Наглядное руководство по стратегиям эволюции» blog.otoro.net. Октябрь 2017 г.
[4] Daan Wierstra, et al. «Стратегии естественной эволюции». Всемирный конгресс IEEE по вычислительному интеллекту, 2008 г.
[5] Агустинус Кристиади. «Естественный градиентный спуск», март 2018 г.
[6] Разван Паскану и Йошуа Бенжио. «Пересмотр естественного градиента для глубоких сетей». Препринт arXiv arXiv: 1301.3584 (2013).
[7] Тим Салиманс и др. «Эволюционные стратегии как масштабируемая альтернатива обучению с подкреплением». Препринт arXiv arXiv: 1703.03864 (2017).
[8] Эдоардо Конти и др. «Улучшение стратегий исследования эволюции для глубокого обучения с подкреплением с помощью популяции ищущих новизну агентов». NIPS. 2018.
[9] Алоис Пуршо и Оливье Сиго. «CEM-RL: сочетание эволюционных и градиентных методов для поиска политики» .» ICLR 2019.
[10] Шаухарда Хадка и Каган Тумер. «Управляемый эволюцией политический градиент в обучении с подкреплением».
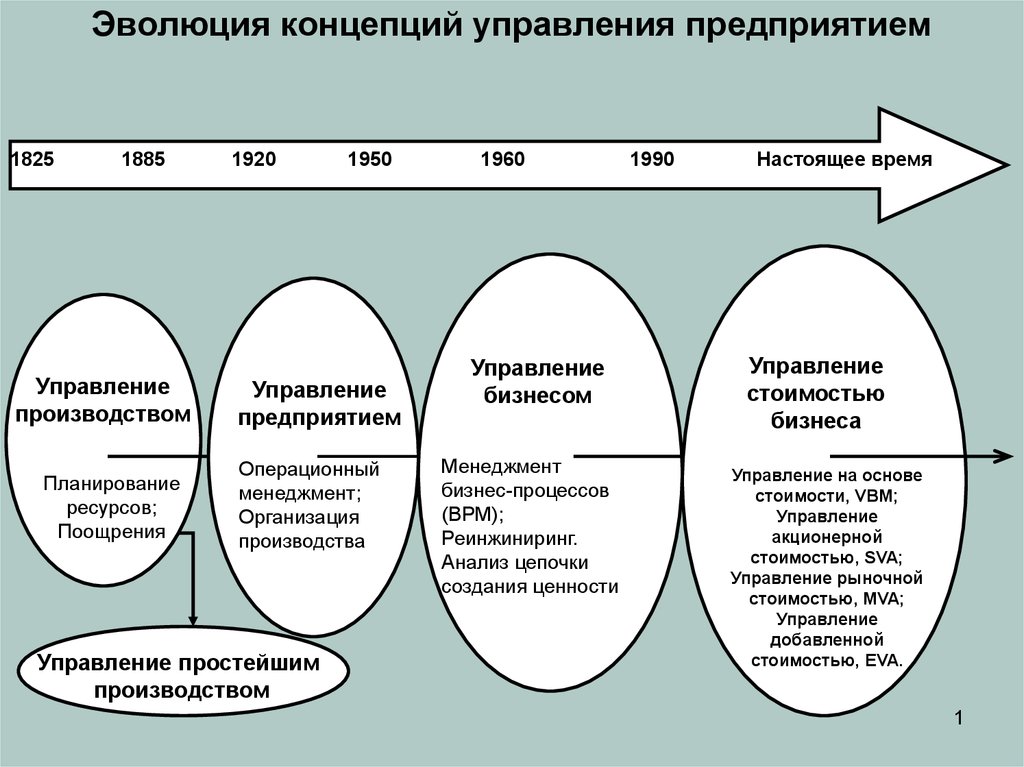 NIPS 2018.
NIPS 2018.[11] Макс Джадерберг и др. «Обучение нейронных сетей на основе популяции». Препринт arXiv arXiv: 1711.09846 (2017).
[12] Адам Гайер и Дэвид Ха. «Независимые от веса нейронные сети». Препринт arXiv arXiv: 1906.04358 (2019).
Стратегии эволюции как масштабируемая альтернатива обучению с подкреплением
Мы обнаружили, что стратегии эволюции (ES) , метод оптимизации, известный на протяжении десятилетий, конкурирует по производительности со стандартными методами обучения с подкреплением (RL) на современных тестах RL (например, Atari/MuJoCo), преодолевая при этом многие неудобства RL.
В частности, ES проще в реализации (нет необходимости в обратном распространении), его проще масштабировать в распределённом сеттинге, он не страдает в сеттингах с разреженными вознаграждениями и имеет меньше гиперпараметров. Этот результат удивителен, потому что ES напоминает простое восхождение на холм в многомерном пространстве, основанное только на конечных разностях в нескольких случайных направлениях на каждом шаге.
Посмотреть на GitHubПросмотреть на arXiv
Наше открытие продолжает современную тенденцию достижения высоких результатов с помощью идей, которым уже несколько десятков лет. Например, в 2012 году статья AlexNet показала, как проектировать, масштабировать и обучать сверточные нейронные сети (CNN) для достижения чрезвычайно хороших результатов в задачах распознавания изображений, в то время как большинство исследователей считали CNN неперспективным подходом к распознаванию изображений. компьютерное зрение. Точно так же в 2013 году статья Deep Q-Learning показала, как объединить Q-Learning с CNN для успешного решения игр Atari, оживив RL как область исследований с захватывающими экспериментальными (а не теоретическими) результатами. Точно так же наша работа демонстрирует, что ES обеспечивает высокую производительность в тестах RL, развеивая распространенное мнение о том, что методы ES невозможно применить к многомерным задачам.
ES легко внедрить и масштабировать. Работая на вычислительном кластере из 80 машин и 1440 ядер ЦП, наша реализация способна обучить трехмерного человекоподобного шагохода MuJoCo всего за 10 минут (A3C на 32 ядрах занимает около 10 часов).
 Используя 720 ядер, мы также можем получить сравнимую с A3C производительность на Atari, сократив время обучения с 1 дня до 1 часа.
Используя 720 ядер, мы также можем получить сравнимую с A3C производительность на Atari, сократив время обучения с 1 дня до 1 часа.Ниже мы сначала кратко опишем традиционный подход RL, сравним его с нашим подходом ES, обсудим компромиссы между ES и RL и, наконец, выделим некоторые из наших экспериментов.
Давайте кратко рассмотрим, как работает RL. Предположим, нам дали некоторую среду (например, игру), в которой мы хотели бы обучить агента. Чтобы описать поведение агента, мы определяем функцию политики (мозг агента), которая вычисляет, как агент должен действовать в той или иной ситуации. На практике политика обычно представляет собой нейронную сеть, которая принимает текущее состояние игры в качестве входных данных и вычисляет вероятность совершения любого из разрешенных действий. Типичная функция политики может иметь около 1 000 000 параметров, поэтому наша задача сводится к тому, чтобы найти точную настройку этих параметров, чтобы политика работала хорошо (т. е. выигрывала много игр).
Вверху: в игре Pong политика может брать пиксели экрана и вычислять вероятность перемещения ракетки игрока (зеленая справа) вверх, вниз или ни разу.
Процесс обучения политике работает следующим образом. Начиная со случайной инициализации, мы позволяем агенту некоторое время взаимодействовать с окружающей средой и собираем эпизоды взаимодействия (например, каждый эпизод — это одна игра в понг). Таким образом, мы получаем полную запись того, что произошло: с какой последовательностью состояний мы столкнулись, какие действия мы предприняли в каждом состоянии и какова была награда на каждом шаге. В качестве примера ниже приведена диаграмма трех эпизодов, каждый из которых занимает 10 временных шагов в гипотетической среде. Каждый прямоугольник — это состояние, а прямоугольники окрашены в зеленый цвет, если награда была положительной (например, мы только что пропустили мяч мимо соперника), и в красный цвет, если награда была отрицательной (например, мы пропустили мяч):
Эта диаграмма предлагает рецепт того, как мы можем улучшить политику; что бы мы ни делали до зеленых штатов, это было хорошо, и что бы мы ни делали в штатах, ведущих к красным областям, было плохо.
 Затем мы можем использовать обратное распространение, чтобы вычислить небольшое обновление параметров сети, которое сделает действия зеленого цвета более вероятными в этих состояниях в будущем, а действия красного цвета менее вероятными в этих состояниях в будущем. Мы ожидаем, что в результате обновленная политика будет работать немного лучше. Затем мы повторяем процесс: собираем еще одну партию эпизодов, делаем еще одно обновление и т. д.
Затем мы можем использовать обратное распространение, чтобы вычислить небольшое обновление параметров сети, которое сделает действия зеленого цвета более вероятными в этих состояниях в будущем, а действия красного цвета менее вероятными в этих состояниях в будущем. Мы ожидаем, что в результате обновленная политика будет работать немного лучше. Затем мы повторяем процесс: собираем еще одну партию эпизодов, делаем еще одно обновление и т. д.Исследование путем добавления шума в действия. Политики, которые мы обычно используем в RL, являются стохастическими, поскольку они вычисляют только вероятности совершения какого-либо действия. Таким образом, в процессе обучения агент может много раз оказаться в том или ином состоянии, и в разное время он будет выполнять разные действия из-за выборки. Это обеспечивает сигнал, необходимый для обучения; некоторые из этих действий приведут к хорошим результатам и будут поощряться, а некоторые из них не сработают и вызовут разочарование.
 Поэтому мы говорим, что вводим исследование в процесс обучения, вводя шум в действия агента, что мы делаем путем выборки из распределения действий на каждом временном шаге. Это будет отличаться от ES, который мы опишем далее.
Поэтому мы говорим, что вводим исследование в процесс обучения, вводя шум в действия агента, что мы делаем путем выборки из распределения действий на каждом временном шаге. Это будет отличаться от ES, который мы опишем далее.Стратегии развития
На тему «Эволюция». Прежде чем мы углубимся в подход ЭС, важно отметить, что, несмотря на слово «эволюция», ЭС имеет очень мало общего с биологической эволюцией. Ранние версии этих методов могли быть вдохновлены биологической эволюцией, и на абстрактном уровне этот подход можно рассматривать как выборку популяции людей и предоставление возможности успешным людям диктовать распределение будущих поколений. Однако математические детали настолько сильно абстрагированы от биологической эволюции, что лучше всего думать об ЭС просто как о классе методов стохастической оптимизации черного ящика.
Оптимизация черного ящика. В ES мы полностью забываем, что существует агент, среда, что задействованы нейронные сети или что взаимодействия происходят во времени и т.
 д. Вся установка состоит в том, что 1 000 000 чисел (которые описывают параметры политики сети) заходим, выходит 1 номер (общая награда), и мы хотим найти наилучшую настройку из 1 000 000 номеров. Математически мы бы сказали, что оптимизируем функцию
д. Вся установка состоит в том, что 1 000 000 чисел (которые описывают параметры политики сети) заходим, выходит 1 номер (общая награда), и мы хотим найти наилучшую настройку из 1 000 000 номеров. Математически мы бы сказали, что оптимизируем функцию f(w)по отношению к входному векторуw(параметры/веса сети), но мы не делаем никаких предположений о структуреf, за исключением того, что можем ее оценить (отсюда «черный ящик»).Алгоритм ЭС. Интуитивно оптимизация представляет собой процесс «угадай и проверь», в котором мы начинаем с некоторых случайных параметров, а затем несколько раз 1) немного корректируем предположение случайным образом и 2) немного сдвигаем наше предположение в сторону тех настроек, которые сработали лучше. Конкретно, на каждом шаге мы берем вектор параметров
Вверху: процесс оптимизации ES в настройках только с двумя параметрами и функцией вознаграждения (красный = высокий, синий = низкий). На каждой итерации мы показываем текущее значение параметра (белым цветом), совокупность дрожащих выборок (черным цветом) и предполагаемый градиент (белая стрелка).wи сгенерировать совокупность, скажем, 100 немного отличающихся друг от друга векторов параметровw1 ... w100путем дрожанияwс гауссовским шумом. Затем мы независимо оцениваем каждого из 100 кандидатов, запуская соответствующую сеть политик в среде на некоторое время, и суммируем все награды в каждом случае. Затем обновленный вектор параметров становится взвешенной суммой 100 векторов, где каждый вес пропорционален общему вознаграждению (т. е. мы хотим, чтобы более успешные кандидаты имели более высокий вес). Математически вы заметите, что это также эквивалентно оценке градиента ожидаемого вознаграждения в пространстве параметров с использованием конечных разностей, за исключением того, что мы делаем это только по 100 случайным направлениям. Еще один способ увидеть это заключается в том, что мы все еще используем RL (Policy Gradients или, в частности, REINFORCE), где действия агента заключаются в том, чтобы испускать целые векторы параметров с использованием гауссовой политики.
Затем мы независимо оцениваем каждого из 100 кандидатов, запуская соответствующую сеть политик в среде на некоторое время, и суммируем все награды в каждом случае. Затем обновленный вектор параметров становится взвешенной суммой 100 векторов, где каждый вес пропорционален общему вознаграждению (т. е. мы хотим, чтобы более успешные кандидаты имели более высокий вес). Математически вы заметите, что это также эквивалентно оценке градиента ожидаемого вознаграждения в пространстве параметров с использованием конечных разностей, за исключением того, что мы делаем это только по 100 случайным направлениям. Еще один способ увидеть это заключается в том, что мы все еще используем RL (Policy Gradients или, в частности, REINFORCE), где действия агента заключаются в том, чтобы испускать целые векторы параметров с использованием гауссовой политики. Мы продолжаем перемещать параметры вверх по стрелке, пока не сойдемся к локальному оптимуму. Вы можете воспроизвести этот рисунок с помощью этого блокнота.
Мы продолжаем перемещать параметры вверх по стрелке, пока не сойдемся к локальному оптимуму. Вы можете воспроизвести этот рисунок с помощью этого блокнота.Образец кода. Чтобы конкретизировать основной алгоритм и подчеркнуть его простоту, вот краткий пример оптимизации квадратичной функции с использованием ES (или см. более длинную версию с дополнительными комментариями):
# простой пример: минимизация квадратичного уравнения вокруг некоторой точки решения импортировать numpy как np решение = np.массив ([0,5, 0,1, -0,3]) def f(w): return -np.sum((w - решение)**2) npop = 50 # размер популяции сигма = 0,1 # стандартное отклонение шума альфа = 0,001 # скорость обучения w = np.random.randn(3) # начальное предположение для я в диапазоне (300): N = np.random.randn(npop, 3) R = np.zeros (npop) для j в диапазоне (npop): w_try = w + сигма*N[j] R[j] = f(w_try) A = (R - np.mean (R)) / np.std (R) w = w + альфа/(npop*sigma) * np.dot(NT, A)Внесение шума в параметры.
 Обратите внимание, что цель идентична той, которую оптимизирует RL: ожидаемое вознаграждение. Однако RL вводит шум в пространство действий и использует обратное распространение для вычисления обновлений параметров, в то время как ES вводит шум непосредственно в пространство параметров. Другой способ описать это так: RL — это «угадывание и проверка» действий, а ES — «угадывание и проверка» параметров. Поскольку мы добавляем шум в параметры, можно использовать детерминированные политики (что мы и делаем в наших экспериментах). Также можно добавить шум как в действия, так и в параметры, чтобы потенциально объединить два подхода.
Обратите внимание, что цель идентична той, которую оптимизирует RL: ожидаемое вознаграждение. Однако RL вводит шум в пространство действий и использует обратное распространение для вычисления обновлений параметров, в то время как ES вводит шум непосредственно в пространство параметров. Другой способ описать это так: RL — это «угадывание и проверка» действий, а ES — «угадывание и проверка» параметров. Поскольку мы добавляем шум в параметры, можно использовать детерминированные политики (что мы и делаем в наших экспериментах). Также можно добавить шум как в действия, так и в параметры, чтобы потенциально объединить два подхода.Компромиссы между ES и RL
ES обладает многочисленными преимуществами по сравнению с алгоритмами RL (некоторые из них немного технические):
- Нет необходимости в обратном распространении . ES требует только прямой передачи политики и не требует обратного распространения (или оценки функции значения), что на практике делает код короче и в 2-3 раза быстрее.
 В системах с ограниченной памятью также нет необходимости вести запись эпизодов для последующего обновления. Также не нужно беспокоиться о взрывных градиентах в RNN. Наконец, мы можем исследовать гораздо более широкий класс функций политик, включая недифференцируемые сети (например, бинарные сети) или сети, включающие сложные модули (например, поиск пути или различные уровни оптимизации).
В системах с ограниченной памятью также нет необходимости вести запись эпизодов для последующего обновления. Также не нужно беспокоиться о взрывных градиентах в RNN. Наконец, мы можем исследовать гораздо более широкий класс функций политик, включая недифференцируемые сети (например, бинарные сети) или сети, включающие сложные модули (например, поиск пути или различные уровни оптимизации). - Высокая параллелизация. ES требует, чтобы рабочие передавали друг другу лишь несколько скаляров, в то время как в RL необходимо синхронизировать целые векторы параметров (которые могут состоять из миллионов чисел). Интуитивно это происходит потому, что мы контролируем случайные начальные значения для каждого рабочего, поэтому каждый рабочий может локально реконструировать возмущения других рабочих. Таким образом, все, что нам нужно для общения между рабочими, — это награда за каждое возмущение. В результате мы наблюдали линейное ускорение в наших экспериментах, когда мы добавляли к оптимизации порядка тысячи ядер ЦП.

- Повышенная надежность. Некоторые гиперпараметры, которые трудно установить в реализациях RL, не используются в ES. Например, RL не является «безмасштабным», поэтому можно добиться очень разных результатов обучения (включая полный провал) с разными настройками гиперпараметра пропуска кадров в Atari. Как мы показываем в нашей работе, ES одинаково хорошо работает с любым пропуском кадров.
- Структурированная разведка. Некоторые алгоритмы RL (особенно градиенты политик) инициализируются со случайными политиками, что часто проявляется как случайное дрожание на месте в течение длительного времени. Этот эффект смягчается в Q-Learning из-за эпсилон-жадных политик, где операция max может заставить агентов выполнять какое-то согласованное действие в течение некоторого времени (например, удерживать нажатой стрелку влево). Это с большей вероятностью что-то сделает в игре, чем если агент дергается на месте, как в случае с градиентами политик.
 Подобно Q-обучению, ES не страдает от этих проблем, потому что мы можем использовать детерминированные политики и добиваться последовательного исследования.
Подобно Q-обучению, ES не страдает от этих проблем, потому что мы можем использовать детерминированные политики и добиваться последовательного исследования. - Присвоение кредита на длительный срок. Путем математического изучения оценок градиента как ES, так и RL мы видим, что ES является привлекательным выбором, особенно когда количество временных шагов в эпизоде велико, когда действия имеют долгосрочные последствия или если нет хороших оценок функции ценности.
И наоборот, мы также обнаружили некоторые проблемы с применением ES на практике. Одна из основных проблем заключается в том, что для того, чтобы ES работал, добавление шума в параметры должно приводить к разным результатам для получения некоторого градиентного сигнала. Как мы подробно рассказали в нашей статье, мы обнаружили, что использование виртуальной пакетной нормы может помочь решить эту проблему, но необходима дальнейшая работа по эффективной параметризации нейронных сетей, чтобы они имели переменное поведение в зависимости от шума.
 В качестве примера связанной трудности мы обнаружили, что в «Мести Монтесумы» очень маловероятно получить ключ на первом уровне со случайной сетью, в то время как это иногда возможно со случайными действиями.
В качестве примера связанной трудности мы обнаружили, что в «Мести Монтесумы» очень маловероятно получить ключ на первом уровне со случайной сетью, в то время как это иногда возможно со случайными действиями.ES конкурирует с RL
Мы сравнили производительность ES и RL в двух стандартных тестах RL: задачи управления MuJoCo и игра Atari. Каждая задача MuJoCo (см. примеры ниже) содержит физически смоделированную сочлененную фигуру, где политика получает положения всех суставов и должна выводить крутящие моменты, которые необходимо приложить к каждому суставу, чтобы двигаться вперед. Ниже приведены несколько примеров агентов, обученных трем задачам управления MuJoCo, целью которых является продвижение вперед:
Мы обычно сравниваем производительность алгоритмов, рассматривая их эффективность обучения на данных; в зависимости от того, сколько состояний мы видели, какова наша средняя награда? Вот примеры кривых обучения, которые мы получаем по сравнению с RL (в данном случае алгоритмом TRPO):
Сравнение эффективности данных .
 Приведенные выше сравнения показывают, что ES (оранжевый) может достигать производительности, сравнимой с TRPO (синий), хотя не во всех случаях полностью соответствует или превосходит его. Кроме того, при горизонтальном сканировании мы видим, что ES менее эффективен, но не хуже, чем примерно в 10 раз (обратите внимание, что ось x находится в логарифмическом масштабе).
Приведенные выше сравнения показывают, что ES (оранжевый) может достигать производительности, сравнимой с TRPO (синий), хотя не во всех случаях полностью соответствует или превосходит его. Кроме того, при горизонтальном сканировании мы видим, что ES менее эффективен, но не хуже, чем примерно в 10 раз (обратите внимание, что ось x находится в логарифмическом масштабе).Сравнение настенных часов . Вместо того, чтобы смотреть на количество наблюдаемых состояний, можно утверждать, что наиболее важной метрикой, на которую следует обратить внимание, является время настенных часов: сколько времени (в секундах) требуется для решения данной проблемы? Эта величина в конечном итоге диктует достижимую для исследователя скорость итерации. Поскольку ES требует незначительного взаимодействия между рабочими, мы смогли решить одну из самых сложных задач MuJoCo (3D-гуманоид), используя 1440 процессоров на 80 машинах всего за 10 минут. Для сравнения, в обычных условиях 32 работника A3C на одном компьютере решали бы эту задачу примерно за 10 часов.
 Также возможно, что производительность RL также может быть улучшена за счет дополнительных алгоритмических и инженерных усилий, но мы обнаружили, что наивное масштабирование A3C в стандартной настройке облачного ЦП является сложной задачей из-за высоких требований к пропускной способности связи.
Также возможно, что производительность RL также может быть улучшена за счет дополнительных алгоритмических и инженерных усилий, но мы обнаружили, что наивное масштабирование A3C в стандартной настройке облачного ЦП является сложной задачей из-за высоких требований к пропускной способности связи.Ниже приведены несколько видео трехмерных человекоподобных ходячих, обученных с помощью ES. Как мы видим, результаты довольно сильно различаются в зависимости от того, к какому локальному минимуму сходится оптимизация.
В Atari ES, обученный на 720 ядрах за 1 час, достигает производительности, сравнимой с A3C, обученной на 32 ядрах за 1 день. Ниже приведены некоторые фрагменты результатов на Pong, Seaquest и Beamrider. Эти видеоролики показывают предварительно обработанные кадры, и это именно то, что агент видит во время воспроизведения:
В частности, обратите внимание, что подводная лодка в Seaquest правильно учится всплывать, когда уровень кислорода достигает низкого уровня.

ES — это алгоритм из литературы по нейроэволюции, который имеет долгую историю в области ИИ, и полный обзор литературы выходит за рамки этого поста. Тем не менее, мы рекомендуем заинтересованному читателю ознакомиться с Wikipedia, Scholarpedia и обзорной статьей Юргена Шмидхубера (раздел 6.6). Работа, которая наиболее точно повлияла на наш подход, — это «Стратегии естественной эволюции» Вирстры и др. 2014. По сравнению с этой работой и большей частью работы, которую она вдохновила, наше внимание сосредоточено на масштабировании этих алгоритмов до крупномасштабных распределенных настроек, поиске компонентов, которые улучшают работу алгоритмов с глубокими нейронными сетями (например, виртуальная пакетная норма), и оценивая их на современных тестах RL.
Также стоит отметить, что подходы, связанные с нейроэволюцией, недавно пережили некоторое возрождение в литературе по машинному обучению, например, с HyperNetworks, «Крупномасштабная эволюция классификаторов изображений» и «Свертка за эволюцией».

Заключение
Наша работа предполагает, что подходы нейроэволюции могут конкурировать с методами обучения с подкреплением в современных тестах агент-среда, предлагая при этом значительные преимущества, связанные со сложностью кода и простотой масштабирования для крупномасштабных распределенных настроек. Мы также ожидаем, что можно будет проделать более интересную работу, пересмотрев другие идеи из этого направления работы, такие как косвенные методы кодирования или развитие структуры сети в дополнение к параметрам.
Примечание по обучению с учителем . Также важно отметить, что эти результаты напрямую не влияют на задачи обучения с учителем (например, классификацию изображений, распознавание речи или большинство других отраслевых задач), где можно вычислить точный градиент функции потерь с обратным распространением. Например, в наших предварительных экспериментах мы обнаружили, что использование ES для оценки градиента в задаче распознавания цифр MNIST может быть в 1000 раз медленнее, чем использование обратного распространения ошибки.
 Только в настройках RL, где приходится оценивать градиент ожидаемого вознаграждения путем выборки, ES становится конкурентоспособным.
Только в настройках RL, где приходится оценивать градиент ожидаемого вознаграждения путем выборки, ES становится конкурентоспособным.Выпуск кода . Наконец, если вы хотите попробовать запустить ES самостоятельно, мы рекомендуем вам погрузиться во все подробности, прочитав нашу статью или просмотрев наш код в этом репозитории Github.
Введение в стратегию эволюции | by Abhijeet Biswas
Обучение нейронной сети без обратного распространения с использованием стратегии развития
В этом посте мы научимся обучать нейронную сеть без обратного распространения с использованием стратегий развития (ES) в Python с нуля на наборе данных MNIST Handwriting Digit. Эта простая реализация поможет нам лучше понять концепцию и применить ее к другим подходящим настройкам. Давайте начнем!
Оглавление
1. Численная оптимизация
2. Стратегии развития
3. Внедрение Vanilla
4. Реализация Python с нуля
5.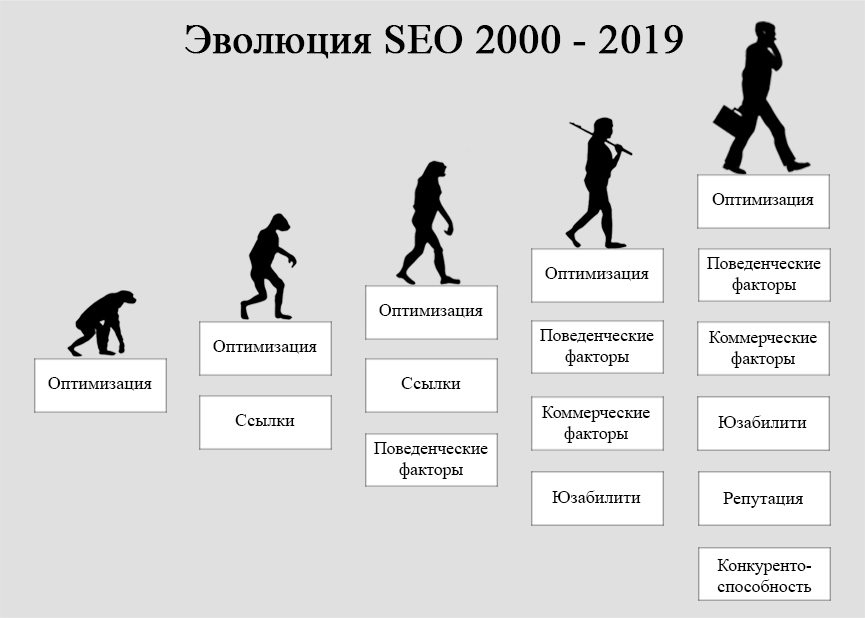 Заключительное примечание
Заключительное примечаниеЧисленная оптимизация
Почти каждый алгоритм может быть представлен как алгоритм машинного обучения проблема с оптимизацией. В алгоритме ML мы обновляем параметры модели, чтобы минимизировать потери. Например, каждый алгоритм обучения с учителем может быть записан как θ_estimate = argmin 𝔼[L(y,f(x,θ))], где x и y представляют функции и цель соответственно, θ представляет параметры модели, f представляет собой функцию, которую мы пытаемся смоделировать, а L представляет функцию потерь, которая измеряет, насколько хорошо мы подходим. Алгоритм градиентного спуска, также известный как метод наискорейшего спуска, в большинстве случаев хорошо решает такие задачи. Это итерационный алгоритм первого порядка для нахождения локального минимума дифференцируемой функции. Мы делаем шаги, пропорциональные отрицательному значению градиента функции Loss в текущей точке, т. е. θ_new = θ_old — α*∇ L(y, f(x, θ_old)). Метод Ньютона — это еще один итерационный метод второго порядка, который сходится за меньшее количество итераций, но требует больших вычислительных ресурсов, поскольку необходимо вычислить обратную производную второго порядка функции потерь (матрица Гессе), т.
Источник: Google Images (-1) * ∇ L(y, f(x, θ_old)). Мы ищем параметр, используя градиенты, так как считаем, что это приведет нас в направлении, в котором потери будут уменьшены. Но можно ли искать оптимальные параметры, не вычисляя никаких градиентов? На самом деле, есть много способов решить эту проблему! Существует множество различных алгоритмов оптимизации без производных (также известных как оптимизация черного ящика).
(-1) * ∇ L(y, f(x, θ_old)). Мы ищем параметр, используя градиенты, так как считаем, что это приведет нас в направлении, в котором потери будут уменьшены. Но можно ли искать оптимальные параметры, не вычисляя никаких градиентов? На самом деле, есть много способов решить эту проблему! Существует множество различных алгоритмов оптимизации без производных (также известных как оптимизация черного ящика).Evolution Strategies
Градиентный спуск не всегда решает наши проблемы. Почему? Короче говоря, локальный оптимум. Например, в случае сценариев разреженного вознаграждения в обучении с подкреплением, когда агент получает вознаграждение в конце эпизода, как в шахматах с конечным вознаграждением в виде +1 или -1 за победу или поражение в игре соответственно. Если мы проиграем игру, мы не узнаем, играли ли мы ужасно неправильно или просто допустили небольшую ошибку. Сигнал градиента вознаграждения в значительной степени неинформативен и может поставить нас в тупик.
 Вместо использования зашумленных градиентов для обновления наших параметров мы можем прибегнуть к методам без производных, таким как стратегии эволюции (ES). ES хорошо работает в таких случаях, а также там, где мы не знаем точную аналитическую форму целевой функции или не можем вычислить градиенты напрямую.
Вместо использования зашумленных градиентов для обновления наших параметров мы можем прибегнуть к методам без производных, таким как стратегии эволюции (ES). ES хорошо работает в таких случаях, а также там, где мы не знаем точную аналитическую форму целевой функции или не можем вычислить градиенты напрямую.В этой статье OpenAI показано, что ES легче внедрять и масштабировать в распределенной вычислительной среде, он не страдает в случае редкого вознаграждения и имеет меньше гиперпараметров. Более того, они обнаружили, что ES обнаружил более разнообразные политики по сравнению с традиционным алгоритмом обучения с подкреплением.
ES — это вдохновленные природой методы оптимизации, в которых используются случайные мутации, рекомбинация и отбор, применяемые к популяции индивидуумов, содержащих решения-кандидаты, с целью последовательного развития лучших решений. Это действительно полезно для нелинейных или невыпуклых задач непрерывной оптимизации.
В ES нас мало волнует функция и ее связь с входными данными или параметрами.
 В алгоритм входит несколько миллионов чисел (параметров модели), и он выдает 1 значение (например, потеря в контролируемой среде; вознаграждение в случае обучения с подкреплением). Мы пытаемся найти лучший набор таких чисел, который возвращает хорошие значения для нашей задачи оптимизации. Мы оптимизируем функцию J(θ) по параметрам θ, просто оценивая ее, не делая никаких предположений о структуре J, отсюда и название «оптимизация черного ящика». Давайте углубимся в детали реализации!
В алгоритм входит несколько миллионов чисел (параметров модели), и он выдает 1 значение (например, потеря в контролируемой среде; вознаграждение в случае обучения с подкреплением). Мы пытаемся найти лучший набор таких чисел, который возвращает хорошие значения для нашей задачи оптимизации. Мы оптимизируем функцию J(θ) по параметрам θ, просто оценивая ее, не делая никаких предположений о структуре J, отсюда и название «оптимизация черного ящика». Давайте углубимся в детали реализации!Ванильная реализация
Для начала мы случайным образом генерируем параметры и настраиваем их так, чтобы параметры работали немного лучше. Математически на каждом шаге мы берем вектор параметров θ и генерируем совокупность, скажем, 100 слегка отличающихся друг от друга векторов параметров θ₁, θ₂… θ₁₀₀ путем флуктуации θ гауссовым шумом. Затем мы независимо оцениваем каждого из 100 кандидатов, запуская модель и на основе выходного значения оцениваем потери или целевую функцию. Затем мы выбираем N самых эффективных элитных параметров, N может быть, скажем, 10, берем среднее значение этих параметров и называем его нашим лучшим параметром на данный момент.
 Затем мы повторяем описанный выше процесс, снова генерируя 100 различных параметров, добавляя гауссов шум к нашему лучшему параметру, полученному на данный момент.
Затем мы повторяем описанный выше процесс, снова генерируя 100 различных параметров, добавляя гауссов шум к нашему лучшему параметру, полученному на данный момент.Думая с точки зрения естественного отбора, мы создаем популяцию параметров (видов) случайным образом и выбираем лучшие параметры, которые хорошо работают на основе нашей целевой функции (также известной как функция пригодности). Затем мы объединяем лучшие качества этих параметров, взяв их среднее значение (это грубый способ, но он все же работает!) и называем это нашим лучшим параметром. Затем мы воссоздаем популяцию, изменяя этот параметр, добавляя случайный шум, и повторяем весь процесс до сходимости.
Источник: адаптировано из тематической энциклопедии Lur, через Викисклад шум к лучшему параметру
— Оценить целевую функцию для всех параметров и выбрать лучшие N лучших параметров (элитные параметры)
— Лучший параметр = Среднее (верхние N элитных параметров)
— Уменьшить шум в конце каждой итерации на некоторый коэффициент (в начале больше шума поможет нам лучше исследовать, но по мере достижения точки сходимости мы хотим, чтобы шум был минимальным, чтобы не отклоняться) Источник : https://en. wikipedia.org/wiki/CMA-ES. Изображение основано на работе Николауса Хансена и других.
wikipedia.org/wiki/CMA-ES. Изображение основано на работе Николауса Хансена и других.
Сферический ландшафт оптимизации изображен сплошными линиями с одинаковыми значениями f. В этом простом примере популяция (точки) концентрируется над глобальным оптимумом после нескольких итераций.Реализация Python с нуля
Давайте рассмотрим простой пример на Python, чтобы лучше понять. Я попытался добавить детали, связанные с численной стабильностью, а также для нескольких вещей. Пожалуйста, прочитайте комментарии! Мы начнем с загрузки необходимых библиотек и набора данных рукописных цифр MNIST.
# Импорт всех необходимых библиотек
import numpy as np
import matplotlib.pyplot as plt
import tqdm
import pickle
import warnings
warnings.filterwarnings('ignore')
from keras.datasets import mnist# Machine Epsilon (необходим для вычисления логарифмов)
eps = np.finfo(np.float64).eps# Загрузка набора данных MNIST
(x_train, y_train), ( x_test, y_test) = mnist.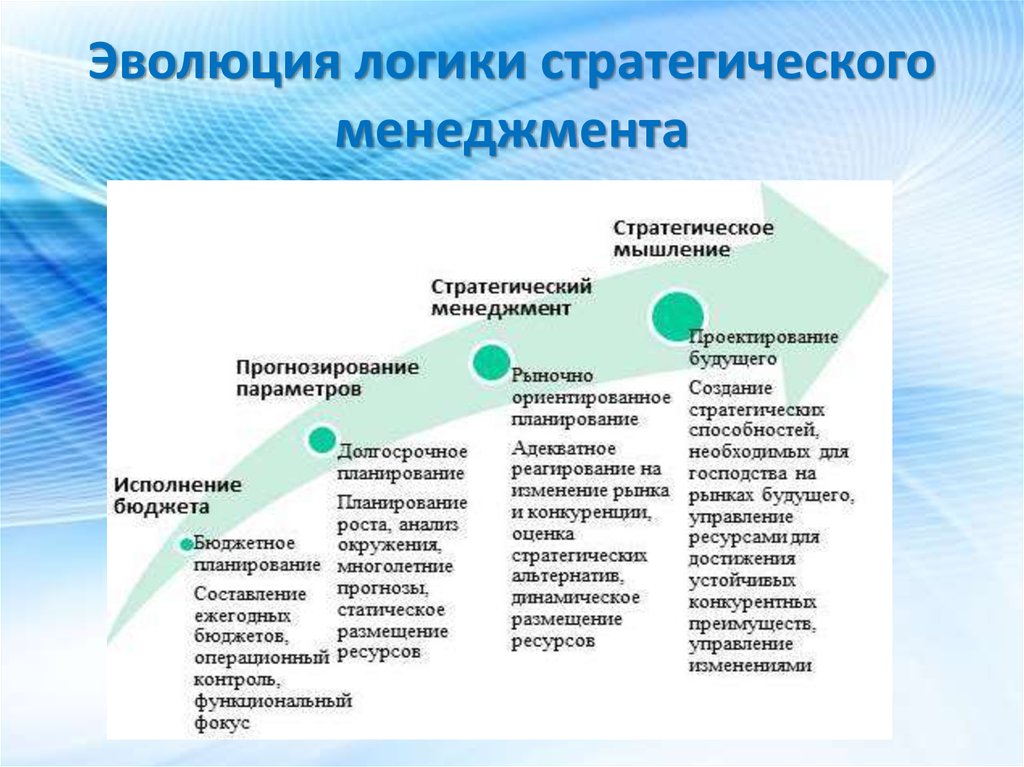 load_data()# x содержит изображения (функции нашей модели)
load_data()# x содержит изображения (функции нашей модели)
# y содержит метки от 0 до 9# Нормализация входных данных между 0 и 1
x_train = x_train/255.
x_test = x_test/255.# Сглаживание изображения при использовании
# плотных нейронных сетей
x_train = x_train.reshape(-1, x_train.shape[1]*x_train.shape[2])
x_test = x_test.reshape(-1, x_test.shape[1]*x_test.shape[2])# Преобразование к горячему представлению
identity_matrix = np.eye(10)
y_train = identity_matrix[y_train]
y_test = identity_matrix[y_test]# Построение изображений
fig, ax = plt.subplots(2,5)
для i, ax в enumerate(ax.flatten()):
im_idx = np.argwhere(y_train == i)[0]
plottable_image = np.reshape(x_train[im_idx], (28, 28))
ax.set_axis_off()
ax.imshow(plottable_image, cmap='gray')plt.savefig('mnist.jpg')
Вот как выглядят изображения,
MNIST Набор рукописных цифр Примеры изображенийМы начнем с определения нашей модели, которая будет представлять собой однослойную нейронную сеть только с прямым проходом.

def soft_max(x):'''
Аргументы: массив numpyВозвращает: массив numpy после применения функции
softmax к каждому элементу
'''# Вычитание максимума x из каждого элемента x для числового
# стабильность, так как это приводит к тому, что наибольший аргумент
# exp равен 0, что исключает возможность переполнения
# Подробнее об этом читайте по адресу:
# https://www.deeplearningbook.org/contents/numerical.htmle_x = np.exp(x — np.max(x))
return e_x /e_x.sum()class Model():'''
Однослойная нейронная сеть'''
def __init__(self, input_shape, n_classes):
# Количество выходных классов
self.n_classes = n_classes# Параметры/веса нашей сети, которую мы будем обновлять
self.weights = np.random.randn(input_shape, n_classes)def forward(self,x):
'''
Аргументы: массив numpy, содержащий функции,
ожидаемая форма входного массива
(размер пакета , количество признаков)Возвращает: массив numpy, содержащий вероятность,
ожидаемая форма выходного массива
(размер пакета, количество классов)'''
# Умножение весов на входы
x = np. dot( x,self.weights)
dot( x,self.weights) # Применение функции softmax к каждой строке
x = np.apply_along_axis(soft_max, 1, x)return x
def __call__(self,x):
'''
Эта функция dunder
позволяет вызывать вашу модельКогда модель вызывается используя модель (x),
прямой метод модели вызывается внутри'''
return self.forward(x)
def Assessment(self, x, y, weights = None):
''' Аргументы: x — пустой массив формы (размер пакета, количество функций),
y — пустой массив формы (размер пакета, количество классов),
weights — массив numpy, содержащий параметры моделиВозвращает: Скаляр, содержащий среднее значение категориальной кросс-энтропийной потери
партии''', если weights не None:
self.weights = weights
# Вычисление отрицательной потери перекрестной энтропии (поскольку
# мы максимизируем этот показатель)
# Добавление небольшого значения, называемого epsilon
# для предотвращения -inf в выводеlog_predicted_y = np.
 log(self.forward(x) + ипс)
log(self.forward(x) + ипс) return (log_predicted_y*y).mean()
Теперь мы определим нашу функцию, которая будет принимать модель в качестве входных данных и обновлять ее параметры.
def optimise(model,x,y,
top_n = 5, n_pop = 20, n_iter = 10,
sigma_error = 1, error_weight = 1, Decay_rate = 0,95,
min_error_weight = 0,01 ):'''
Аргументы: model — Объект модели (здесь однослойная нейронная сеть),
x — пустой массив формы (размер пакета, количество функций),
y — пустой массив формы (размер пакета, количество классов),
top_n — Количество элитных параметров, которые необходимо учитывать для расчета наилучшего параметра
путем получения среднего Вклад ошибки при рассмотрении новой популяции
delay_rate — Скорость, с которой вес ошибки будет уменьшаться после
каждой итерации, чтобы мы не отклонялись на
0359 точка схождения. Он управляет балансом между
исследованием и эксплуатациейВозвращает: Объект модели с обновленными параметрами/весами
'''
# Веса модели были сначала случайным образом инициализированы
best_weights = model. weights
weights for i in range(n_iter )0013
# Оценка совокупности параметров
Assessment_values = [model.evaluate(x,y,weight) для веса в pop_weights]# Сортировка на основе оценки
weight_eval_list = zip(evaluation_values, pop_weights)weight_eval_list, key = lambda x: x[0], reverse = True)
Assessment_values, pop_weights = zip(*weight_eval_list)
# Берем среднее значение элитных параметров
best_weights = np.stack(pop_weights[:top_n], ось=0).среднее(ось=0)#Затухание веса
error_weight = max(error_weight*decay_rate, min_error_weight)model.weights = best_weights
return model# Создание объекта нашей модели
model = Model(input_shape= x_train.shape[-1], n_classes= 10) print("Оценка обучающих данных", model.evaluate(x_train, y_train))# Запуск на 200 шагов
для i в tqdm.tqdm(range(200)):model = optimise(model,
x_train ,
y_train,
top_n = 10,
n_pop = 100,
n_iter = 1)print("Кросс-энтропийные потери тестовых данных: ", -1*model.
 evaluate(x_test, y_test))
evaluate(x_test, y_test))
print("Точность теста: ",(np.argmax(model(x_test)), axis=1) == y_test).mean())# Сохранение модели для последующего использования
с помощью open('model.pickle','wb') as f:
pickle.dump(model,f)Результаты : После обучения в течение 200 итераций точность теста составила ~ 85%, а кросс-энтропийная потеря ~ 0,28. Это сравнимо с однослойной нейронной сетью, обученной с обратным распространением. Обратите внимание, что здесь мы даже не использовали затухание, так как n_iter было установлено равным 1,9.0013
Заключительное примечаниеES очень просты в реализации и не требуют градиентов. Просто вводя шум в наши параметры, мы можем искать пространство параметров. Несмотря на то, что мы решили его для контролируемой задачи для простоты понимания, он больше подходит для сценариев обучения с подкреплением, где необходимо оценить градиент ожидаемого вознаграждения путем выборки.
Надеюсь, вам понравилось читать этот пост!
Другие технические блоги можно найти на моем веб-сайте: Dig Deep ML
Ссылки и дополнительная литература :
Сообщение в блоге OpenAI
Блог Оторо
Блог Лилиан
Пришло время для нового пути
Вы столкнулись с проблемой реализации стратегии? Ты не одинок.
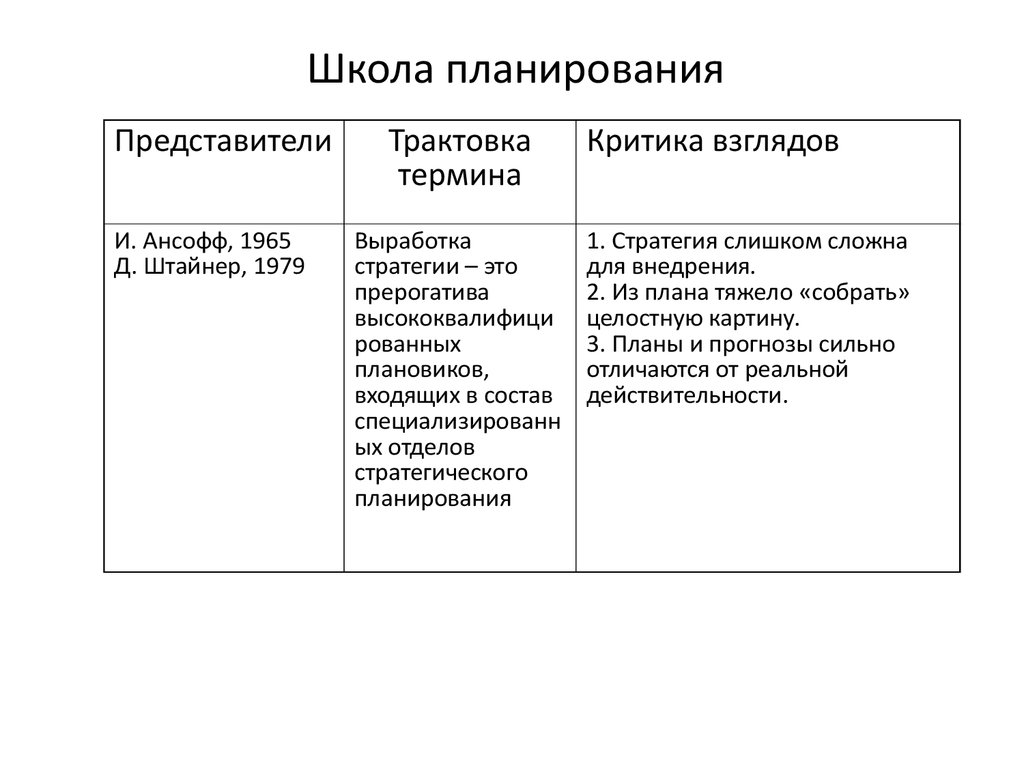 В большинстве компаний самые продуманные планы падают, как свинцовые шарики.
В большинстве компаний самые продуманные планы падают, как свинцовые шарики.В течение многих лет по слухам ходили слухи, что до 90% стратегий терпят крах и сгорают.
Эволюция стратегии в прошлом веке обнадеживает. Но прямо сейчас эффективное стратегическое мышление остается непреодолимым лабиринтом для большинства компаний.
Старый способ не работает — одни разговоры и никаких действий. После бравады презентации менеджеры, создавшие план, начинают работать, а сотрудники, которые никогда не видели и не понимали план, теряются.
Без какой-либо видимости или принятия решений в процессе стратегического планирования люди на передовой не чувствуют связи с видением. Таким образом, когда «Великая отставка» идет полным ходом, миллионы незанятых сотрудников переходят в компании, которые могут похвастаться удаленной рабочей средой, инновационными идеями и инклюзивной культурой, которые придают большее значение своей работе.
Тем не менее, так быть не должно.
 Вам не нужно терять свои цели, конкурентное преимущество, видение или лучшие таланты — если вы принимаете эволюцию стратегии.
Вам не нужно терять свои цели, конкурентное преимущество, видение или лучшие таланты — если вы принимаете эволюцию стратегии.Время революции. Приходите, мы покажем вам новый способ планирования, реализации и отслеживания стратегии.
Эволюция стратегического планированияВот как потерпеть неудачу при планировании стратегии старым добрым способом:
Вы собираете небольшую группу руководителей высшего звена, которые контролируют корпоративную стратегию. Это их детище, и пусть Бог спасет всех, кто посмеет к нему прикоснуться, особенно Мэтта из финансового отдела (этот парень всегда бросает гаечный ключ в работу!).
Ваша первоклассная команда закрывает двери зала заседаний, задвигает ставни и прокладывает себе путь к секретному генеральному плану, который понравится всем остальным (по крайней мере, вы так думаете). Если вы сможете совершить набег на казну компании без нытья Ника, вы наймете консультанта, чтобы быстро взглянуть.
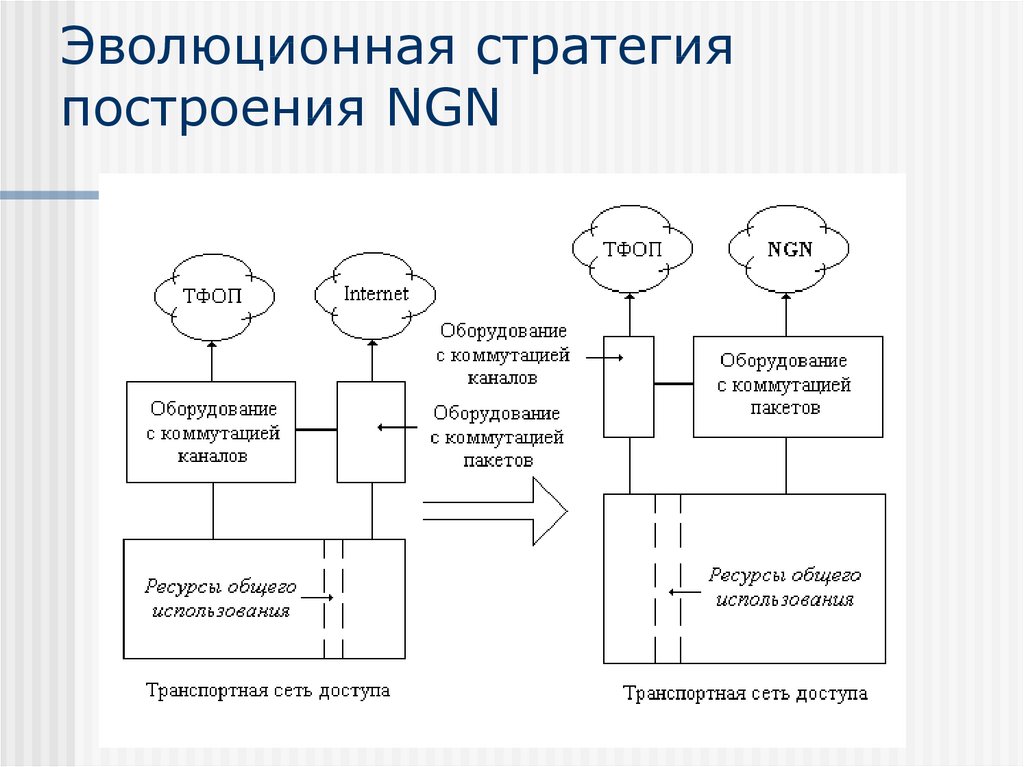 Затем вы предоставите генеральному директору и его безумным навыкам работы с Excel возможность оживить стратегию перед большим открытием.
Затем вы предоставите генеральному директору и его безумным навыкам работы с Excel возможность оживить стратегию перед большим открытием.На ежемесячном совещании команды ваши сотрудники бредут в зал заседаний и обнаруживают головокружительных руководителей, сгрудившихся перед проектором. Менеджеры по очереди бегают по презентации, диктуя расплывчатые сообщения, прыгая по слайдам и чертя стрелки на доске. Генеральный директор завершает кратким изложением множества инструментов, которые команда должна использовать, чтобы «держаться на правильном пути».
Когда слайд-шоу заканчивается, наступает тишина. Менеджеры обвиняют офисную молнию в ошеломленном и растерянном выражении лиц, а затем возвращают их к работе, прежде чем люди зададут вопросы. В то время как аналитические центры поздравляют друг друга с хорошо выполненной работой, генеральный директор записывает стратегию в готовую папку на своем ноутбуке, а затем все продолжают ошибаться, не имея ни малейшего представления о том, как воплотить свое видение в жизнь.

К сожалению, этот фарс стал реальностью для многих компаний сегодня. Нисходящий подход к стратегии опирается на автономные электронные таблицы, блокноты, доски и сторонние инструменты. Хуже всего то, что эта бестолковая миссия поручается разрозненным командам, которые не понимают, что им нужно делать. «Главные стратеги» в зале заседаний совета директоров никогда не спрашивали мнение сотрудников.
В двух словах: это старый способ реализации стратегии, который сводится к причудливому плану, не предназначенному для действий.
Сюрприз, сюрприз, не получилось. Быстро и жестко.
По данным McKinsey,
72% руководителей утверждают, что они привлекают своих сотрудников к созданию стратегии. Но некоторые из этих лидеров рассказывают о свинине, так как только 56% сотрудников согласны с этим, а 29% категорически не согласны.
Итак, что происходит, когда вы привлекаете своих людей?
Новый (и усовершенствованный) способ стратегического планирования
Представьте себе компанию, в которой топ-менеджеры бросают дым, а зеркала действуют и передают бразды правления людям.
 Руководители не выступают напоказ, и между командами нет разногласий. Вы отделяете устаревшие процессы и системы и создаете конкурентную стратегию, которая может оказать влияние.
Руководители не выступают напоказ, и между командами нет разногласий. Вы отделяете устаревшие процессы и системы и создаете конкурентную стратегию, которая может оказать влияние.Как?
Вы делаете стратегию делом каждого. Это всенаправленная модель, в которой мыслящие сверху вниз встречаются с исполнителями снизу вверх. И где каждый в компании имеет право голоса в планировании стратегии (да, даже Мэтт).
Это радикально человеческое отношение адаптируется к людям в вашей организации, принимая во внимание их мысли и взгляды на то, как должна работать стратегия. В конце концов, люди на передовой — это самые близкие к вашему клиенту люди, поэтому они могут знать кое-что, чего не знают шишки в зале заседаний.
С платформой для реализации стратегии вы можете попрощаться с разрозненными системами и объединить все стратегии под одной крышей. Вся эта хрень не заперта на компьютере генерального директора — она доступна для всех команд, в любое время и из любого места.

Что делать, если люди делают что-то впервые и не уверены в процессе? Потом вы их учите. По мере того, как вы повышаете квалификацию своих сотрудников, чтобы они могли максимально эффективно использовать свое положение в компании, вы даете им возможность выполнять более значимую работу.
Больше никаких переходов между компьютерами, документами или инструментами.
Больше никаких запутанных электронных таблиц Excel или презентаций PowerPoint.
Больше никаких ошеломленных или растерянных взглядов на лицах ваших сотрудников.
Все просто для доступа, понимания и выполнения, что способствует культуре обмена информацией и стимулированию инноваций. Вы экономите время, деньги, разочарования, и все становится на свои места.
Звучит мечтательно, правда?
В Cascade мы считаем, что компании должны мечтать о большем и добиваться лучших результатов. Пришло время жить мечтой!
Эволюция реализации стратегииСлышали ли вы историю о компании, которая разработала план в PowerPoint, держала все стратегические вопросы в зале заседаний и все же сумела приспособиться к стремительным изменениям в своей вечной жизни? развивающийся рынок, как кот-ниндзя на доске для серфинга?
Нет? Мы тоже.

Как ни странно, этот сценарий резюмирует старую философию стратегического управления. Когда люди наверху не могут привлечь всех к работе и настаивают на устаревших инструментах и настольных версиях планов вместо современной платформы для реализации стратегии, компания много теряет.
Вместо того, чтобы получить основу для роста и достижения своих целей, вы остаетесь в беспорядке:
- Нет организации деятельности, целей и обязанностей
- Нет связи между повседневной деятельностью и зрением
- Нет ясности в том, как реализовать идеи
- Нет легкого доступа и видимости для всех
- Нет согласования между всеми вашими командами
Планы не станут реальностью, если люди не знают, как их реализовать или даже не получат к ним доступ. Вчерашние технологии не могут дать вам ясного представления о будущем, просто спросите у Kodak.
Фотокомпании принадлежало 80 % рынка в 1968 году. Но когда цифровой прорыв поднял голову, Kodak стояла на месте.
 Компания предпочла придерживаться аналоговых технологий, несмотря на волну поддержки цифровых камер. К тому времени, когда компания перешла к адаптации своей бизнес-стратегии, было уже слишком поздно. Разрушители захватили рынок и оставили некогда грозного гиганта на полу. Kodak подала заявление о банкротстве в 2012 году.
Компания предпочла придерживаться аналоговых технологий, несмотря на волну поддержки цифровых камер. К тому времени, когда компания перешла к адаптации своей бизнес-стратегии, было уже слишком поздно. Разрушители захватили рынок и оставили некогда грозного гиганта на полу. Kodak подала заявление о банкротстве в 2012 году.Все могло бы быть совсем иначе, если бы стратегия компании основывалась на принципах быстрой адаптации и инноваций. Они могли бы дать отпор инновациями, как это сделали IKEA, Dyson и Ford. Эти компании поняли, что если вы хотите преуспеть в реализации стратегии, вы должны выбрать новый путь.
Новый (и усовершенствованный) способ реализации стратегии
Что, если мы скажем вам, что существует способ разработки стратегии, при котором каждый знает, как его работа способствует видению компании? Способ, с помощью которого вы всегда можете держать всех на одной волне.
Правильно: мы говорим о полном согласовании во всех отделах и всех командах.

Самым большим препятствием, мешающим командам выполнять стратегические планы, является не плохое руководство; дело в том, что всему проекту не хватает ясности и инклюзивности. Большинство людей не чувствуют, что они владеют стратегией. Даже если и понимают, то не понимают. Письменные планы и реальность сотрудников — разные миры.
Если вы измените способ разработки стратегии и переведете своих сотрудников на первый этаж с бизнес-политикой, идеями и технологиями, которые вы хотите использовать, вы сможете упростить каждое взаимодействие человека и машины.
Разрабатывайте стратегию по-новому, предоставляя всем ясность, необходимую им для достижения максимального эффекта в своих ролях. У них будет контекст, необходимый им, чтобы увидеть общую картину и понять важность своей роли в общем движении.
Эволюция измерения стратегического успехаРазве ты не любишь, когда план воплощается в жизнь? Конечно, все мы испытываем это теплое, пушистое чувство, когда наша команда пересекает финишную черту в крупной кампании.
 Дело в том, что когда дело доходит до реализации стратегии, ваши планы никогда не « просто складываются».
Дело в том, что когда дело доходит до реализации стратегии, ваши планы никогда не « просто складываются».В то время как некоторые руководители думают, что они обладают сверхспособностями, правда в том, что вы не можете засунуть стратегию компании в пыльную папку Dropbox и надеяться, что она когда-нибудь автоматически принесет плоды.
Если вы не отслеживаете свои действия и их влияние, как узнать, приближает ли каждое действие вас к финишу? Как узнать, движется ли вообще ваша команда в правильном направлении? Вы можете просто стоять на месте или бесцельно шататься.
Измерение стратегического успеха — это не просто хорошая идея — это действие, требующее решения «сделай или умри» (ну, по крайней мере, для целей вашей организации). Тем не менее, так много компаний возятся с этой устаревшей системой. У них есть план, но нет средств для измерения прогресса.
Они могли бы попробовать новые инструменты, но их удерживает перспектива обучения и отслеживания всех показателей.
 Итак, они придерживаются того, что знают, штампуя череду разрозненных, полусырых электронных таблиц и слайд-шоу, которые почти мгновенно отправляются во внешнюю галактику сознания компании.
Итак, они придерживаются того, что знают, штампуя череду разрозненных, полусырых электронных таблиц и слайд-шоу, которые почти мгновенно отправляются во внешнюю галактику сознания компании.Хуже того, когда они пытаются внедрить новые инструменты, их вдруг становится пять или шесть. И эти разрозненные инструменты не могут дать нам целостной картины. Допустим, Мэтт наконец дал добро на внедрение инструментов управления проектами и бизнес-аналитики. Однако, глядя на цифры в инструментах BI, мы не можем понять, как они отражают прошлые проекты. И чем больше у вас инструментов, тем больше они отрываются от вашей стратегии.
Какой проект способствовал резкому росту доходов от подписки, когда 5 команд одновременно работали как минимум над 3 проектами? В то время как бизнес думает, что они получают необходимую информацию, реальность такова, что они просто смотрят на цифры без какого-либо контекста.
«Это то, что мы всегда делали, — говорят они, — нет нужды что-то менять, потому что это всегда работало на нас» (хотя это и не работало…).

Раз в месяц стажер уберет кучу дубликатов файлов, многие из которых уже устарели, и свалит все в одну папку. Люди будут хлопать его по плечу, пока не заглянут внутрь папки и не увидят 17 очень похожих документов — все с броскими названиями вроде «Стратегия версия 2.3 — резервная копия 12b».
Этот хаос возникает, когда у вас нет правильной стратегии. Старый способ фокусируется на тактике, но ему не хватает направления. Это заставляет вашу команду барахтаться и отчаянно барахтаться, не имея никакого представления о том, как все это должно собраться вместе.
Это методология пожаротушения, поскольку ваша команда реагирует на проблемы, а не заблаговременно предупреждает их и провоцирует сбои.
При использовании старого способа разработки стратегии и измерения прогресса ваш бизнес быстро постигнет поражение. Без ясности, направления и сплоченности команды все ваши усилия не оправдают своего максимального потенциала.
Должен быть лучший способ, верно?
Новый (и усовершенствованный) способ измерения стратегии
Нам бы хотелось сказать вам, что мы собираемся взорвать ваш мозг, но это было бы ложью.
 Правда в том, что исправление вашего причудливого подхода к стратегии, похожего на коробку Пандоры, до безобразия простое:
Правда в том, что исправление вашего причудливого подхода к стратегии, похожего на коробку Пандоры, до безобразия простое:Вы храните все, что имеет значение для вашей стратегии, в одном месте.
У вас есть ОДИН инструмент для стратегического планирования, реализации, и измерений.
Вот и все — это новый стиль.
Вау. Мы знаем, верно? Только подумайте об этом:
- Нет больше цифровой усталости, когда вы жонглируете инструментами бизнес-аналитики, аналитическим программным обеспечением, Google Drive, Dropbox и ноутбуком генерального директора.
- Больше никаких головоломных сессий, когда вы пытаетесь заполнить пробелы, когда все «просто забыли» отслеживать прогресс в течение месяца.
- Больше никакой путаницы с последними версиями ваших стратегических активов или приоритетом действий в любой конкретный день или неделю.
- Больше никаких утомительных и трудоемких миссий по поиску дубликатов документов.
Всего один инструмент, который поможет вам увидеть статус вашей стратегии в режиме реального времени и упростит ее адаптацию, обновление и внедрение инноваций.

Всего один инструмент, чтобы управлять ими всеми.
«Но, но, но существует ли такой мифический зверь?» вы нажимаете.
Да, старый друг. Присаживайтесь сюда, и позвольте нам показать вам то, что действительно поразит вас.
Стратегическая революция: как Cascade меняет правила игрыЕсли вы хотите раскрыть потенциал своей команды, чтобы вносить важные изменения, добиваться поставленных целей и бороться с разрушителями в вашем пространстве, то пришло время принять новый способ разработки стратегии.
Вот как мы помогаем компаниям сделать это:
- Empower Strategy Activists: Наша модель поможет вам разрушить бункеры между командами. Жизненно важные коммуникации больше не проскальзывают в щели. Вы делаете стратегию делом каждого и помогаете каждому найти возможности для повышения ценности и принятия изменений.
- Поощряйте культуру видения Драйверы: 90 % стратегий не будут реализованы С помощью Cascade вы можете превратить свою стратегию в действие, обеспечив выполнение на месте.

- Помощь людям в работе Значение: Вовлеченные сотрудники понимают, как их работа влияет на общую картину и согласуется с видением компании. По мере того, как ваша компания приспосабливается к пониманию уникальных проблем и опыта, с которыми сталкиваются люди, вы придаете больше смысла своей повседневной деятельности.
- Бросьте вызов способу реализации стратегий: Чем дольше вы цепляетесь за существующие системы, тем меньше вы растете. Мы помогаем вам переосмыслить будущее вашего бизнеса и сделать вашу организацию быстрой и гибкой, постоянно фокусируясь на инновациях в масштабах всего предприятия и взрывном росте.
Старый способ разработки стратегии должен уйти. Если вы придерживаетесь устаревшей идеологии «сверху вниз» (с ее уединенными группами и таблицами Excel), то у вас может вообще не быть целей.
Стратегия без исполнения — всего лишь гипотеза.
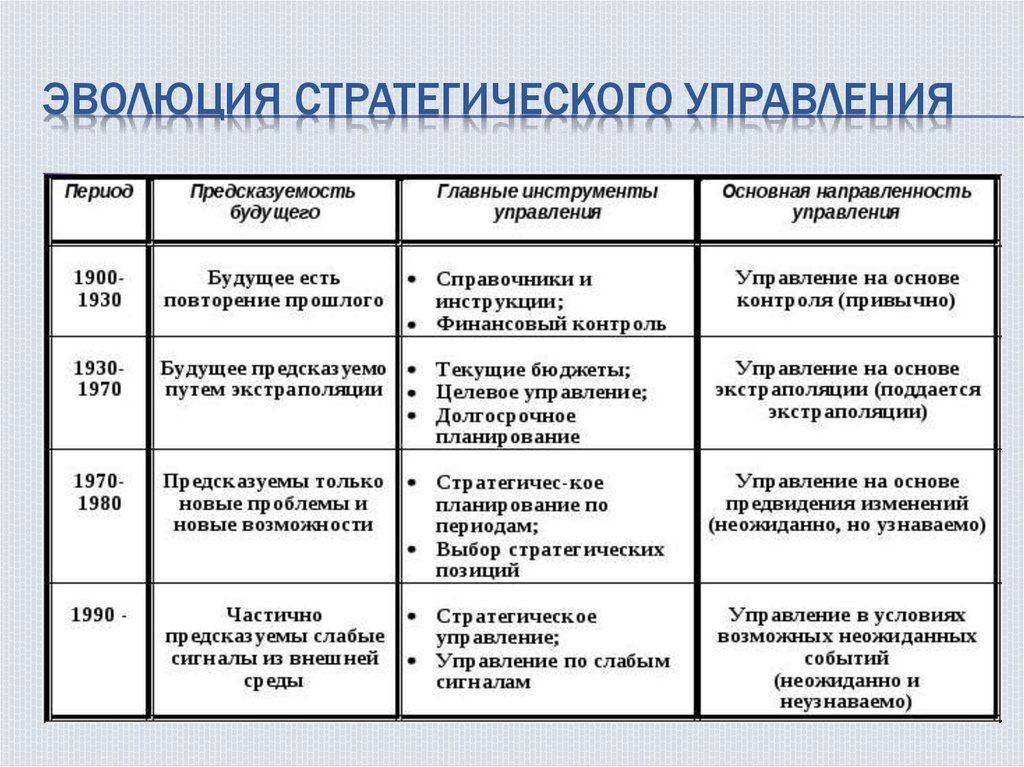 Как беззубая собака, лает и не кусается. Если ваш бизнес хочет добиться успеха благодаря реализации стратегии, когда идеи доводятся до реализации, пришло время подумать не только о зале заседаний и доске.
Как беззубая собака, лает и не кусается. Если ваш бизнес хочет добиться успеха благодаря реализации стратегии, когда идеи доводятся до реализации, пришло время подумать не только о зале заседаний и доске.Ваша стратегия должна процветать среди тех, кто ее реализует, а не среди тех, кто сидит в залах заседаний. Ваша стратегия должна постоянно распространяться, вовлекаться и доводиться до сведения всех, чтобы ее можно было адаптировать вместе с командами, которые ее реализуют.
Готовы ли вы изменить то, как вы сталкиваетесь со стратегией? Посетите наш вебинар по запросу , чтобы понять, почему пора мечтать о большем и добиваться большего.
Стратегии эволюции: до неприличия параллельная оптимизация
30 марта 2017 г.
Я смотрел выступление Ильи Суцкевера об их новой эволюционной стратегии. Вот бумага:
- Salimans et al (2017) Стратегии развития как масштабируемая альтернатива обучению с подкреплением
Причина, по которой эта статья интересна, заключается в том, что они используют относительно тупой, простой стохастический метод оптимизации, который не должен хорошо работать на практике, и показывают, что он на самом деле конкурентоспособен с методами, основанными на SGD/обратном распространении в RL.
 В основном это связано с тем, что он так естественно распараллеливается. В этом отношении это поучительная статья.
В основном это связано с тем, что он так естественно распараллеливается. В этом отношении это поучительная статья.В этой заметке я объясняю довольно простую математику, лежащую в основе метода, и немного рассказываю о нескольких случайных идеях, которые могут еще больше повысить эффективность метода:
- производные второго порядка
- выборка по важности для уменьшения дисперсии
- повторное использование образцов из предыдущих шагов
- Байесовская оптимизация
Предостережение: Я почти уверен, что существует обширная литература по стратегиям эволюции и связанным с ними методам, с которыми я просто не знаком. Этот пост представляет собой сборник моих первых идей, которые у меня возникли после первого знакомства с этой техникой. Весьма вероятно, почти наверняка, что многое из того, о чем я здесь говорю, было сделано раньше — извините, если я пропущу ссылки.
Если вас это интересует, ознакомьтесь также с постом Дэвида Барбера о вариационной оптимизации и ее связях с ES.

Что такое ЭС?
Стратегии развития (ЭС) лучше всего можно описать как метод градиентного спуска, в котором используются градиенты, оцениваемые по стохастическим возмущениям вокруг текущего значения параметра. Хотя авторы проводили сравнения в контексте RL, и у RL есть много специфических преимуществ, здесь я сосредоточусь на ES как на общем методе оптимизации черного ящика. 9{th}$ центральный момент гауссианы всегда равен $0$ при нечетных $p$.
Вот оно. На каждом шаге ES возмущает текущее значение параметра аддитивным гауссовским шумом, оценивает функцию при возмущенных значениях, наконец, объединяет эти значения функции в оценку градиента и делает шаг в этом направлении.
Вот рисунок, взятый из сообщения в блоге OpenAI, наглядно иллюстрирующий, как работает метод для оптимизации 2D-функции:
Когда $\theta$ имеет большую размерность, это приближение может иметь очень высокую дисперсию, поэтому здравый смысл подсказывает, что вы не должны использовать это на практике, особенно когда вы действительно можете вычислять градиенты с помощью обратного распространения.
 Однако статья ES опровергла здравый смысл.
Однако статья ES опровергла здравый смысл.ES может быть очень конкурентоспособным методом в сценариях, когда:
- у вас очень большое количество узлов для распределения вычислений на
- ваше пространство параметров огромно, поэтому пересылка значений параметров между узлами будет дорогостоящей
- вы имеете дело с недифференцируемыми целями, где SGD не совсем работает или требует приближений.
Почти смущающая параллель
Существуют распределенные версии SGD, но они почти всегда должны передавать обновления параметров между узлами или на центральный сервер параметров. Когда ваше пространство параметров огромно, быстрая отправка многомерного $\theta$ по сети становится самым трудоемким занятием, которое вы делаете, немного замедляя все.
Распределенные ES используют разумное наблюдение: каждый рабочий вычисляет $f_i = f(\theta + \epsilon_i)$ для своего собственного $\epsilon_i$. Для оценки градиента нужны все $\epsilon_i$s и все вычисленные значения $f_i$.
 Передача $f_i$ стоит дешево, поскольку они являются скалярами, передача $\epsilon_i$ так же дорога, как передача $\theta$. Однако, поскольку $\epsilon_i$ являются псевдослучайными числами , вам не нужно сообщать эти , предполагая, что работники знают случайное начальное число друг друга. Рабочие могут моделировать генераторы случайных чисел других рабочих локально.
Передача $f_i$ стоит дешево, поскольку они являются скалярами, передача $\epsilon_i$ так же дорога, как передача $\theta$. Однако, поскольку $\epsilon_i$ являются псевдослучайными числами , вам не нужно сообщать эти , предполагая, что работники знают случайное начальное число друг друга. Рабочие могут моделировать генераторы случайных чисел других рабочих локально.Это делает распределенные ES почти до неприличия параллельными, когда в каждом цикле обновления необходимо передавать только отдельные скаляры. Эта экономия времени в сочетании с тем фактом, что мы не делаем обратную опору (которая обычно занимает примерно в два раза больше времени, чем прямой проход), делает ES сверхбыстрым по сравнению с SGD. Таким образом, даже если ваши оценки градиента зашумлены, вы можете сделать гораздо больше зашумленных шагов градиента за тот же период времени. По иронии судьбы, это имеет тот же эффект, что и уменьшение размера пакета в SGD: ваши градиенты становятся более шумными, но вы обновляете их чаще.

Недифференцируемость
SGD имеет дело с целевыми функциями, которые в широком смысле имеют следующую форму:
$$
f(\theta) = \mathbb{E}_{x} f(\theta; x)
$$SGD требует, чтобы все отдельные $f(\theta; x)$ были дифференцируемы относительно. $\theta$ для всех значений $x$. В этом случае вы можете просто поменять местами ожидание с дифференцированием следующим образом:
$$
\frac{\partial}{\partial \theta}f(\theta) = \mathbb{E}_{x} \frac{\partial}{\partial \theta}f(\theta; x)
$$Однако во многих приложениях $f(\theta; x)$ на самом деле не дифференцируема. Примеры включают:
- POMDP/RL с дискретным действием или пространством состояний
- вариационных автоэнкодера с дискретными скрытыми переменными (Jang et al, 2016)
- GAN с дискретными генераторами (Hjelm et al, 2017)
ES по-прежнему работает в этих сценариях, потому что вы можете просто поменять местами ожидания относительно $x$ и $\epsilon$ (в отличие от замены ожидания дифференцированием).

\begin{align}
\mathbb{E}_\epsilon \epsilon f(\theta + \epsilon) &= \mathbb{E}_\epsilon \epsilon \mathbb{E}_{x} f(\theta + \epsilon; x) \\
&= \mathbb{E}_{x} \mathbb{E}_\epsilon \epsilon f(\theta + \epsilon; x)
\end{align}Вот почему ES так эффективен в RL: он может решать проблемы RL способом, который невозможен при явном стохастическом градиентном спуске, потому что вознаграждение в отдельных эпизодах не дифференцируемо относительно параметры политики.
Второй заказ ES
ES на самом деле является частным случаем SGD, а не альтернативой. Наиболее общая формулировка SGD действительно требует только 90 323 несмещенных оценок градиентов 90 324 (несмещенных = зашумленных, но правильных в среднем). В обычном SGD с мини-пакетом и обратным распространением несмещенные, но зашумленные оценки получаются из подвыборки i.i.d. данные. В ES оценки градиента могут быть немного смещены (из-за аппроксимации $f$ как разложения Тейлора 2-го порядка), но для всех практических целей вы можете думать об этом как о несмещенном.
 Основным отличием является источник случайности в оценках градиента: в backprop-SGD это подвыборка данных (мини-пакеты), в ES это случайные возмущения в дополнение к подвыборке данных. В результате, все приемы, которые вы могли бы применить к обратному распространению SGD, вы все равно можете применить к ES и рассчитывать на успех. Авторы показывают, например, что батчнорм, Адам и т. д. все еще работают. 92 5}{2} f»(\theta)
Основным отличием является источник случайности в оценках градиента: в backprop-SGD это подвыборка данных (мини-пакеты), в ES это случайные возмущения в дополнение к подвыборке данных. В результате, все приемы, которые вы могли бы применить к обратному распространению SGD, вы все равно можете применить к ES и рассчитывать на успех. Авторы показывают, например, что батчнорм, Адам и т. д. все еще работают. 92 5}{2} f»(\theta)
\end{align}Конечно, эта оценка может быть необъективной и иметь возмутительно высокую дисперсию. Таким образом, если ваш внешний алгоритм SGD допускает предварительную обработку с информацией о производной второго порядка, вы можете использовать эти оценки, полученные из данных, которые вы уже вычислили бесплатно. Некоторые комментаторы упомянули, что авторы уже используют Адама и пакетную норму, а Адам и пакетная норма уже аппроксимируют поведение второго порядка, поэтому вопрос о том, может ли добавить к этому дополнительная зашумленная оценка гессиана, остается открытым вопросом.
Выборка по важности
Дисперсия оценщика может быть значительно уменьшена с помощью выборки по важности. Вместо выборки $\epsilon$ из изотропного гауссиана можно выбрать его из другого распределения предложений $q$, а затем скорректировать несоответствие между $q$ и гауссианой, введя веса важности:
$$
\mathbb{E}_{\epsilon\sim \mathcal{N}}\left[ \epsilon f(\theta + \epsilon)\right[ = \mathbb{E}_{\epsilon \sim q } \left[\epsilon \frac{\mathcal{N}(\epsilon)}{q(\epsilon)}f(\theta + \epsilon)\right]
$$Пока рабочие знают, что такое распределение предложений $q$, и знают случайное начальное число друг друга, алгоритм по-прежнему легко распараллеливается.
Как мы можем выбрать распределение предложения?
Что ж, можно было бы сделать какое-то предложение, основанное на импульсе. Вместо того, чтобы рисовать $\epsilon$ из гауссианы с $0$-средним значением, можно взять выборку из гауссианы со средним значением $\mu$, где $\mu$ — некоторый импульс градиентного спуска, например, экспоненциально-взвешенное среднее предыдущего градиента.
 оценки. 92\справа)}
оценки. 92\справа)}
$$распределенная байесовская оптимизация
Другая мысль заключается в следующем: как только вы вычислили значение функции в нескольких возмущенных точках, можете ли вы сделать что-то более разумное с этими парами $(\epsilon_i, f_i)$, чем использовать тейлоровское приближение второго порядка? В частности, представьте, что вы можете использовать простое машинное обучение, чтобы выполнить локальную регрессию целевой функции и перейти прямо туда, где вы ожидаете наиболее значительный выигрыш. Конечно, это работает только в том случае, если регрессию и последующие шаги оптимизации можно выполнить очень дешево и быстро, в противном случае вы отнимаете время у других вещей, таких как вычисление производных или оценка функции в большем количестве точек. Но может быть сладкое пятно, где рабочих знают случайное начальное число друг друга Идея может быть применена в более широком смысле в байесовской оптимизации.
Резюме
Эта статья может быть противоречивой, некоторые считают ее чрезмерно раздутой.
 Я не думаю, что это так, я думаю, что в этом что-то есть, и это может быть началом нового направления исследований (ну, в рамках глубокого обучения многие из них, вероятно, уже были сделаны оптимизаторами раньше). Лично я нахожу терминологию «Эволюционные стратегии» весьма неудачной (это название придумали не авторы этой статьи). Я думаю, что для машинного обучения будет гораздо полезнее рассматривать этот метод с точки зрения оценок стохастического градиента, а не как частный случай эволюционных алгоритмов, как следует из названия.
Я не думаю, что это так, я думаю, что в этом что-то есть, и это может быть началом нового направления исследований (ну, в рамках глубокого обучения многие из них, вероятно, уже были сделаны оптимизаторами раньше). Лично я нахожу терминологию «Эволюционные стратегии» весьма неудачной (это название придумали не авторы этой статьи). Я думаю, что для машинного обучения будет гораздо полезнее рассматривать этот метод с точки зрения оценок стохастического градиента, а не как частный случай эволюционных алгоритмов, как следует из названия.Раньше, когда исследователи подвергали сомнению фундаментальные предположения о наших методах, получались очень хорошие результаты: если подумать, замена гладких сигмовидных активаций недифференцируемыми выпрямленными линейными единицами звучит как довольно плохая идея — до тех пор, пока вы на самом деле не поймете, что они работают. Выпадение может показаться чем-то, чего следует избегать, пока вы не поймете, почему это работает. Стохастический градиентный спуск родился из-за необходимости: вы не могли разместить больше определенного количества данных на графическом процессоре, и было непрактично перебирать весь набор данных для каждого обновления градиента.

, где $\sigma$ управляет общим масштабом распределения, часто называемым размером шага .
Прежде чем мы углубимся в то, как обновляются параметры в CMA-ES, лучше сначала рассмотреть, как ковариационная матрица работает в многомерном распределении Гаусса.
 Как реальная симметричная матрица, ковариационная матрица $C$ обладает следующими замечательными свойствами (см. доказательство и доказательство):
Как реальная симметричная матрица, ковариационная матрица $C$ обладает следующими замечательными свойствами (см. доказательство и доказательство):