Локализуем игру в слова с искусственным интеллектом / Хабр
Даже на русском языке игра не самая простая
Все началось с коллеги, который закинул в локальный чат сообщение, что он сыграл в игру #59 и угадал слово с 33 попыток и одной подсказки. Игра оказалась простая и сложная одновременно: сайт загадал слово и нужно его отгадать. В поле ввода отправляешь слово, а искусственный интеллект на сайте определяет, насколько отправленное слово близко по смыслу к загаданному.
Интересная игра, тренирующая ассоциативное мышление и умение строить связи. Новое слово появляется каждый день, что в некотором смысле выглядит ограничителем. Также игра доступна только на португальском и английском языках. С одной стороны, это дополнительная практика, а с другой — сомнения «а знаю ли я это слово?» смазывают впечатления от игры.
Так я задумался о локализации игры на русский язык. Свою игру «Русо контексто» я разместил на объектном хранилище, которое более устойчиво примет читателей Хабра.
Дисклеймер. Оригинальная игра расположена по адресу contexto.me. В процессе подготовки статьи я узнал о существовании русскоязычной версии guess-word.com. Но эта версия имеет более ограниченную функциональность.
Как работает игра?
У сайта минималистичный интерфейс:
- Сведения об игре: номер, количество попыток и количество подсказок.
- Поле ввода слова.
- Список отгаданных слов в виде полосы загрузки. Чем ближе, тем более она заполнена. Номер справа обозначает расстояние в словах, но его можно отключить.
В выпадающем меню есть настройки и дополнительные игровые опции:
- Выбрать игру.
- Взять подсказку.
- Сдаться.
Если отгадать слово, то игра предложит поделиться результатом и взглянуть на ближайшие 500 слов. Игра очень быстро возвращает ответ и умеет определять начальную форму слова. Иными словами, cat и cats считаются одним словом и выводиятся как cat. Все введенные слова трактуются как существительные, и в списке 500 ближайших слов глагола не встретить.
Иными словами, cat и cats считаются одним словом и выводиятся как cat. Все введенные слова трактуются как существительные, и в списке 500 ближайших слов глагола не встретить.
Это наводит на мысль, что список ближайших слов формируется отдельно, а игра просто обращается к списку. Остается вопрос: как составить список ближайших слов?
Текстовые эмбеддинги
Изначально компьютеры не владеют ни одним человеческим языком. Но человек делает все возможное, чтобы это исправить. Человек может сказать одну команду, используя разные слова и в разном порядке. Машине нужно уметь не просто различать слова, но и понимать смысл, который прячется за этими словами.
Здесь на помощь приходят текстовые эмбеддинги. Если упрощать, то эмбеддинг — это превращение слова в набор чисел, который называют кортежем или вектором. Эти числа задают положение слова в виде точки в пространстве, но не в трехмерном, а в многомерном. Чем ближе две точки, тем ближе слова по смыслу, а компьютеры умеют вычислять.
В рамках данной статьи оставим процесс сопоставления слов векторам в виде черного ящика, которым мы хотим пользоваться, но нам неинтересно, как он работает. Однако если любопытство берет верх, то рекомендую ознакомиться со статьями из секции дополнительного чтения в конце текста.
После операции сопоставления появляется модель — файл, который описывает соответствие «слово — вектор» или как-то описывает правила сопоставления или вычисления. Для работы модели нужно программное обеспечение, которое понимает формат модели.
Проще и быстрее всего «потрогать» эмбеддинги на языке Python. Библиотека gensim реализует один из самых популярных подходов — word2vec. Для работы необходима модель, обученная на достаточном количестве текстов. В документации gensim есть ссылки на англоязычные модели, но нас это не устраивает.
К счастью, проект RusVectores предоставляет модели на русском языке. На сайте представлены контекстуализированные и статические модели.
Я использовал модель, обученную на Национальном Корпусе Русского Языка (НКРЯ), ее название — ruscorpora_upos_cbow_300_20_2019. Скачиваем архив и распаковываем. Модель представлена в двух видах: бинарном (model.bin) и текстовом (model.txt).
Попробуем воспользоваться этой моделью. Сперва загружаем.
from gensim.models import KeyedVectors
model = KeyedVectors.load_word2vec_format("model.txt", binary=False)
Теперь можем найти слова, ближайшие к слову «провайдер»:
>>> model.most_similar(positive=["провайдер"]) … KeyError: "Key 'провайдер' not present in vocabulary"
К сожалению, такого слова не нашлось. Дело в том, что данная модель принимает слова вместе с меткой, которая определяет часть слова. Это сделано для различия слов с одинаковым написанием. Например, «печь» можно представить как «печь_NOUN» и «печь_VERB», то есть как существительное и глагол соответственно.
>>> model.most_similar(positive=["провайдер_NOUN"])
[
('ip_PROPN', 0.677890419960022),
('internet_PROPN', 0.6627045273780823),
('интернет_PROPN', 0.6595873832702637),
('интернет_NOUN', 0.6567919850349426),
('веб_NOUN', 0.6510902047157288),
('сервер_NOUN', 0.6460723280906677),
('модем_NOUN', 0.6433334946632385),
('трафик_NOUN', 0.6332165002822876),
('безлимитный_ADJ', 0.6230701208114624),
('ритейлер_NOUN', 0.6218529939651489)
]Также возьмем более простой пример с несколькими словами. Зададим два слова: король и женщина. Человек догадается, что женщина-король — это скорее всего королева.
>>> model.most_similar(positive=["король_NOUN", "женщина_NOUN"], topn=1)
[
('королева_NOUN', 0.6674807071685791),
('королева_ADV', 0.6368524432182312),
('принцесса_NOUN', 0.6262999176979065),
('герцог_NOUN', 0.613500714302063),
('герцогиня_NOUN', 0.5999450087547302)
]
Метод most_similar выводит список наиболее похожих слов и некоторую метрику расстояния до этого слова. Чем ближе метрика к единице, тем ближе слово. Список слов отсортирован по убыванию этой метрики. Так как сортировка производится при выводе, то значение метрики далее мы использовать не будем.
Чем ближе метрика к единице, тем ближе слово. Список слов отсортирован по убыванию этой метрики. Так как сортировка производится при выводе, то значение метрики далее мы использовать не будем.
Аргумент topn позволяет задать количество слов, которые мы хотим получить. Таким образом можно запросить какое-нибудь большое количество слов и получить список, необходимый для создания игры. Давайте зададим более современное слово «киберпространство» и посмотрим на ближайшее слово и на слово, например, на десятитысячной позиции.
>>> result = model.most_similar(positive=["киберпространство_NOUN"], topn=10000)
>>> result[0]
('виртуальный_ADJ', 0.39892229437828064)
>>> result[9998]
('европбыть_VERB', 0.12139307707548141)
>>> result[9999]
('татуировкий_NOUN', 0.12139236181974411)
Наличие специфичных слов, которые могут шуткой, опечаткой, ошибкой в парсинге или локальным жаргонизмом, неприятно влияет на игру.
Более того, использование некорректного тега приведет к интересным результатам
>>> model.most_similar(positive=["европа_NOUN"], topn=10)
[
('максимилиан::александрович_PROPN', 0.3658076822757721),
('фамилие_NOUN', 0.36153605580329895),
('санюшка_NOUN', 0.35595449805259705),
('емельян::ильич_PROPN', 0.35401633381843567),
('автостоп_NOUN', 0.35294172167778015),
('юрген_PROPN', 0.3491175174713135),
('чарльз::диккенс_PROPN', 0.3454093337059021),
('когда-тотец_NOUN', 0.3360745906829834),
('городбыть_VERB', 0.3332841098308563),
('владлен_VERB', 0.33179953694343567)
]
Пояснение: Европа — имя собственное, поэтому тег должен быть PROPN.
Нужно очистить словарь от странных слов и оставить только существительные.
Если вам понравится этот текст, у меня есть еще:→ Подбираем скины в Counter-Strike: Global Offensive в цвет сумочки
→ Делаем тетрис в QR-коде, который работает
→ Делаем радио из Cyberpunk 2077
Обработка словаря
Один из способов хранения модели word2vec — текстовый.
 Формат прост: в первой строке задаются два числа — количество строк в документе и количество чисел в векторе. Далее на каждой строке задается слово и далее числа, обозначающие вектор.
Формат прост: в первой строке задаются два числа — количество строк в документе и количество чисел в векторе. Далее на каждой строке задается слово и далее числа, обозначающие вектор.Здесь удобно воспользоваться особенностью этой модели, а именно тегами. Существительные имеют тег _NOUN, что позволяет убрать из модели ненужные слова. Удалить не существительные легко, но как поступить с опечатками и странными словами? Здесь на помощь приходит другой эмбеддинг, который обучался на литературе.
Это эмбеддинг Navec (навек) из проекта Natasha. Ссылку на русскоязычную модель можно увидеть в репозитории проекта. Скачиваем и загружаем модель:
from navec import Navec path = 'navec_hudlit_v1_12B_500K_300d_100q.tar' navec = Navec.load(path)
Теперь можно проверять слова простым синтаксисом:
>>> "виртуальный" in navec True >>> "европбыть" in navec False >>> "татуировкий" in navec False
Таким образом можно отсеять немалое количество слов, которым в игре не место.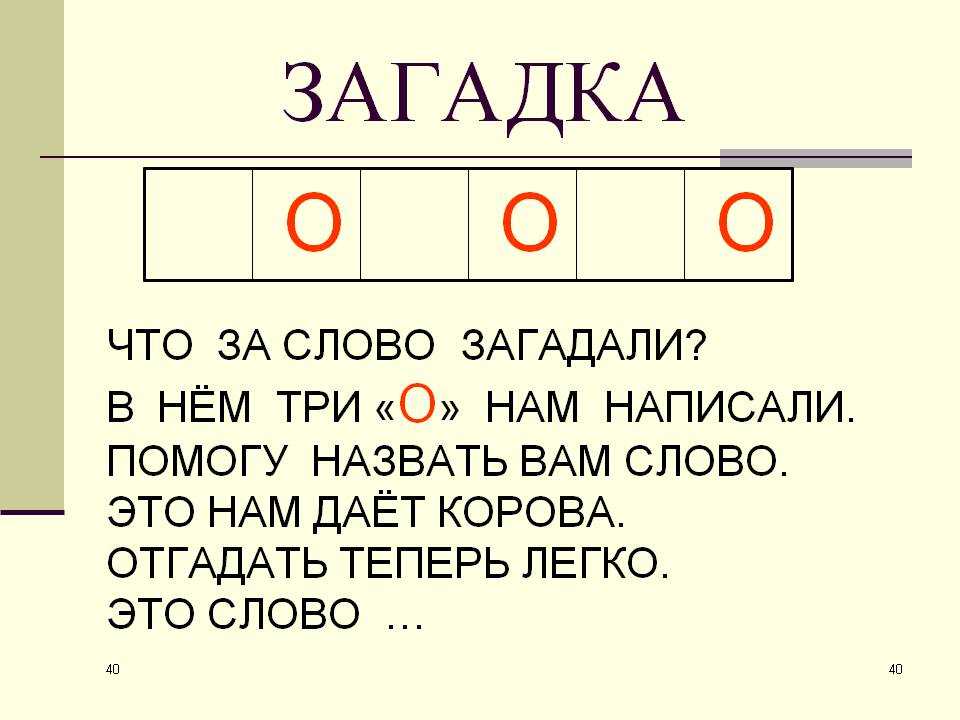
Примеры удаленных слов, многие даже великому гуглу неизвестны
цидулка
зачатокать
магазей
антитезть
завоевателий
налицотец
прируба
бислой
цвть
громадий
межрайонец
англиканствый
скудетто
выбытий
делаловек
чтобль
Но вместе с тем теряются и настоящие слова
агрокомплекс
кейтеринг
фемтосекунда
углепластик
электромашиностроение
мурмолка
реанимобиль
Алгоритм очистки модели следующий:
- Если у слова тег не NOUN, то отбрасываем это слово.
- Удаляем из слова последовательность _NOUN.
- Проверяем «чистое слово» на наличие в эмбеддинге Navec. Если его там нет, слово отбрасываем.
- Слово, которое прошло все проверки, записываем в файл.

После обработки всех слов в первую строку новой модели записываем два числа: количество оставшихся строк и размерность вектора. Размерность вектора при данной обработке остается неизменной. Если все сделано правильно, то очищенную модель получится загрузить:
model = KeyedVectors.load_word2vec_format("noun_model.txt", binary=False)Стало ли после этого лучше?
>>> result = model.most_similar(positive=["киберпространство"], topn=10000)
>>> result[0]
('виртуальность', 0.4715898633003235)
>>> result[9998]
('компаунд', 0.15783849358558655)
>>> result[9999]
('хитрость', 0.15783214569091797)Определенно. Для статистики: исходная модель содержит 248 978 токенов, из них 59 104 токенов имеют метку существительного. И только 36 269 прошли «сито» второго эмбеддинга.
Время заняться бэкэндом и фронтендом игры.
Умный бэкэнд
Так как Python является моим рабочим языком программирования, бэкэнд я решил реализовать на нем. Поговорим об обработке входных данных. Обрезать пробелы и перевести текст в нижний регистр — само собой разумеющееся. Но как получить начальную форму слова?
Здесь можно воспользоваться инструментом MyStem. Для Python есть обертка pymystem3. Крайне простой инструмент для получения начальной формы слова:
import pymystem3 mystem = pymystem3.Mystem()
Метод lemmatize принимает на вход строку-предложение и возвращает список слов в начальной форме.
>>> mystem.lemmatize("кот коты котов котах кота")
['кот', ' ', 'кот', ' ', 'кот', ' ', 'кот', ' ', 'кот', '\n']
На первый взгляд даже производительность на достойном уровне: на моей виртуальной машине лемматизация одного слова занимает до 10 мс. По меркам современного веба это достаточно быстро.
Пока я работал над бэкэндом, по работе пришлось познакомиться с объектным хранилищем, среди функций которого есть возможность размещения статических сайтов. И тут мне пришла интересная мысль.
Игра на объектном хранилище
При разработке бэкэнда я продумывал способы защититься от нечестной игры:
- Сдаться нельзя.
- Список топ-500 ближайших слов получить можно, только предоставив загаданное слово.
- Подсказку можно получить по слову и позиции.
Но вскоре мне показалось это слишком суровым.
На данный момент единственное назначение бэкэнда — приведение слов к начальной форме. Правда, как показало тестирование на коллегах, и это не обязательно: все и так старались писать начальные формы слов. Да и модель эмбеддингов не лемматизирована, то есть игра понимает слова не только в начальной форме.
Получается, игру можно полностью перенести в браузер?
Так как я бэкэнд-разработчик, то отказ от бэкэнда в угоду фронтэнду — это стресс. Однако от бэкэнда полностью отказаться не получится: генератор близких слов где-то нужно запускать. Генератор принимает на вход загаданное слово и формирует текстовый файл, где на каждой строке по одному слову в порядке смыслового убывания от загаданного. Содержимое этого файла также дублируется в JSON-словарь, где каждому слову соответствует его дистанция от загаданного слова.
Однако от бэкэнда полностью отказаться не получится: генератор близких слов где-то нужно запускать. Генератор принимает на вход загаданное слово и формирует текстовый файл, где на каждой строке по одному слову в порядке смыслового убывания от загаданного. Содержимое этого файла также дублируется в JSON-словарь, где каждому слову соответствует его дистанция от загаданного слова.
JSON-файл на каждую игру занимает до 2 МБ. При открытии игры файл скачивается в браузер и JavaScript реализует логику игры. Этот способ не самый производительный, но после загрузки файла позволяет играть без подключения к интернету.
Я разместил игру в облачном хранилище Selectel, которое более устойчиво к наплыву посетителей.
Заключение
Итоговый результат доступен по адресу words.f1remoon.com, а исходный код — в репозитории.
Дополнительное чтение
Как работают текстовые эмбеддинги?
→ Чудесный мир Word Embeddings: какие они бывают и зачем нужны? (от пользователя madrugado)
→ Word2vec в картинках (от пользователя m1rko)
Студенты ИТМО создали игру, в которой нужно угадать слово, поняв логику искусственного интеллекта
При этом, по правилам, секретное слово каждый день новое. За первую неделю игру запустили 31 тысяча уникальных пользователей, а на телеграм-канал проекта подписалось две тысячи человек. Несколько дней назад разработчики запустили версию 2.0 — в первый день в неё сыграли 10 тысяч раз. В чем популярность игры, что вдохновило авторов на ее создание, и какие запросы от пользователей они получают — обсудили с Мичилом Егоровым, студентом 4 курса факультета инфокоммуникационных технологий ИТМО, членом команды Центра учебной аналитики и главным разработчиком игры.
За первую неделю игру запустили 31 тысяча уникальных пользователей, а на телеграм-канал проекта подписалось две тысячи человек. Несколько дней назад разработчики запустили версию 2.0 — в первый день в неё сыграли 10 тысяч раз. В чем популярность игры, что вдохновило авторов на ее создание, и какие запросы от пользователей они получают — обсудили с Мичилом Егоровым, студентом 4 курса факультета инфокоммуникационных технологий ИТМО, членом команды Центра учебной аналитики и главным разработчиком игры.
— Для начала расскажите, как вообще пришла идея создать игру?
— Честно, все получилось неожиданно. Мне в 9 утра написал будущий co-founder Григорий Спиров и сказал, что есть вот такая крутая игра на английском Contexto и было бы круто сделать локализацию на русский язык. Сама игра работает по принципу «горячо-холодно»: чем сильнее ассоциируется введенный игроком вариант с загаданным словом, тем выше он в рейтинге. Раньше я работал NLP-инженером в НЦКР ИТМО (Национальный центр когнитивных разработок ― прим.ред.), так что мне как исследователю было интересно наблюдать отношения слов к друг другу, построенные конкретным алгоритмом.
Раньше я работал NLP-инженером в НЦКР ИТМО (Национальный центр когнитивных разработок ― прим.ред.), так что мне как исследователю было интересно наблюдать отношения слов к друг другу, построенные конкретным алгоритмом.
Так что мы сели разрабатывать проект в тот же день с Григорием, и уже через 11 часов первая версия нашей игры была готова. Перед самым запуском на помощь с дизайном пришла Айталина Кривошапкина ― ей был дан буквально час, чтобы сделать что-то приличное. Так образовалась наша команда из трех человек.
— А можете объяснить работу алгоритма? Во время игры кажется, что он не совсем очевидно подбирает слова.
— Мы изначально хотели сделать именно ассоциативную игру, поэтому между word2vec и Glove (самые популярные и легкие алгоритмы) выбрали последний. Glove пытается ставить ближе друг к другу слова со схожими контекстами. Например, как-то мы загадали слово «водопад» и вторым по близости было не банальное «вода», а слово «ниагарский». Кажется, что эта дополнительная сложность и делает игру интересной.
Кажется, что эта дополнительная сложность и делает игру интересной.
— Какие слова вы загрузили в алгоритм?
— В качестве датасета мы используем тексты художественной литературы — всего у нас в базе более 100 тысяч самых популярных русских слов.
— Ваша игра очень быстро начала набирать популярность, как вы думаете, почему?
— Действительно, в течение первой недели у нас было около 30 тысяч уникальных сессий. Причем из способов продвижения у нас был только один твиттер-аккаунт. Но в первый же день мы попросили посмотреть игру Наталью Давыдову, основательницу сообщества для джунов и фронтендеров (у нее около 15 тысяч подписчиков), она лайкнула наш твит — и за ночь к нам пришло 24 тысячи пользователей. Мы такого совсем не ожидали — и наш слабенький сервер не выдержал такой напор. Пришлось все перезапускать.
Сейчас у нас уже больше ста тысяч сессий — в среднем к нам приходит до 2 тысяч новых игроков в день. Больше всего радует, что люди сами узнают об игре — мы пока что ее никак не рекламируем. Например, я ничего не говорил об этом своим знакомым, а они все равно узнали. Оказывается, о нас написал какой-то телеграм-канал.
Например, я ничего не говорил об этом своим знакомым, а они все равно узнали. Оказывается, о нас написал какой-то телеграм-канал.
Читайте также:
Игры как образование: как студент ИТМО популяризирует культуру коренных народов через компьютерные игры
Студенты ИТМО и жители Петербурга визуализировали имя города с помощью нейросети
— А вы вообще думали о способах продвижения и монетизации?
— У нас есть телеграм-канал, где мы выкладываем подсказки и статистику угадываний за день, сейчас там уже больше 2 тысяч подписчиков. В нем же наши игроки делятся своими результатами, предлагают улучшения, либо сообщают о нестыковках и ошибках.
По поводу монетизации — пока что нам не совсем понятно, что именно следует монетизировать. В качестве теста мы на три дня запускали рекламу и в целом получили неплохие деньги. Но это не коррелирует с нашим видением продукта — нам бы хотелось развивать игру без рекламы. Если мы и будем вводить что-то платное, то это не коснется основного функционала игры. Платным могут стать только дополнительные фичи, например, создание своих комнат с возможностью самому загадывать слово. Но если такое не зайдет пользователям, то придумаем другой вариант. А пока мы просто запустили бусти для желающих поддержать проект.
Если мы и будем вводить что-то платное, то это не коснется основного функционала игры. Платным могут стать только дополнительные фичи, например, создание своих комнат с возможностью самому загадывать слово. Но если такое не зайдет пользователям, то придумаем другой вариант. А пока мы просто запустили бусти для желающих поддержать проект.
— А что вообще вам пишут пользователи, что просят добавить в функционал?
— Наши пользователи активно пишут и предлагают различные идеи. Всех их можно сгруппировать в четыре категории: улучшить алгоритм, расширить базу слов, добавить уровни сложности и добавить возможность играть почаще, в том числе перепроходить старые раунды. Но мы пока сфокусированы на улучшении текущего функционала: нужно сделать интерфейс более user-friendly и проработать айдентику игры.
Еще пользователи предложили реализовать для нас телеграм-бота или мобильное приложение, с некоторыми ребятами мы уже начали сотрудничать. А вообще, мы всегда готовы открыть наше API для желающих сделать свой пет-проект.
— Какие нововведения вы будете запускать в ближайшее время?
— Как раз на днях мы запустили тестирование новой версии игры — поменяли дизайн и добавили новый функционал: тестируем те самые отдельные комнаты, в которых можно играть со своими друзьями. К слову, в первый же день новую версию запустили 10 тысяч человек.
Еще мы получаем объективную критику от пользователей по поводу работы алгоритма, поэтому мы точно будем его менять. Но пока что не знаем, как именно — будем экспериментировать. Например, хотим проверить другие технологии векторизации слов: fast-text, BERT и другие трансформеры. Но BERT очень популярный и относится к тяжелым алгоритмам в плане использования памяти и вычислительной мощности. Еще есть идея запуска нескольких алгоритмов одновременно, но пусть пока это будет секретом.
К началу
Math показывает 3 лучших варианта, чтобы выиграть как можно быстрее
Поскольку популярность Wordle резко возросла, несколько СМИ опубликовали статьи, в которых исследуется, какое слово лучше всего использовать в качестве первоначального предположения.
Часто авторы этих произведений предполагают, что слово должно быть таким, в котором используется как можно больше гласных, оно должно содержать буквы, часто встречающиеся в английском языке, или обладать чертами, регулярно встречающимися в языке.
Что ж, мои студенты-финансисты и я решили решить этот вопрос как можно точнее, определив оптимальное первое слово для игры в Слово .
В ходе нашего анализа были проанализированы все возможные комбинации пятибуквенных слов и выполнено моделирование всех возможных итераций — более 1 миллиона из них — чтобы определить наилучшую начальную стратегию.
«Проверенный» и верный подход
В Wordle у игроков есть шесть попыток угадать слово из пяти букв. Каждый раз, когда игрок делает предположение, он узнает, является ли каждая буква правильной и находится ли она в правильном месте, появляется в слове в другом месте или вообще отсутствует в слове.
У игроков могут быть разные подходы. Некоторые могут просто захотеть разгадать слово, даже если это займет шесть попыток. Другие пытаются сделать это с минимальным количеством догадок.
Некоторые могут просто захотеть разгадать слово, даже если это займет шесть попыток. Другие пытаются сделать это с минимальным количеством догадок.
Основываясь на нашем анализе, если вы пытаетесь выиграть как можно меньше раз, лучше всего использовать три слова: среднее количество попыток произнесения слов составляет 3,90, 3,92 и 3,92 соответственно, если вы используете оптимальную стратегию игры (подробнее об этом позже).
Быстро!
РазговорЕсли, с другой стороны, вы просто пытаетесь выиграть в отведенных шести догадках, то три лучших слова для игры — это «адепт», «зажим» и «плед». Использование любого из этих трех слов даст средний показатель успеха в игре 98,79 %, 98,75 % и 98,75 % соответственно, если вы придерживаетесь оптимальной стратегии.
И в этом заключается первое интересное различие между игрой на победу и игрой на победу с минимальным количеством догадок.
Если вы играете, чтобы выиграть в отведенных шести догадках, лучше всего сыграть слово, в котором есть только одна гласная и четыре согласных, поскольку в шести из 10 лучших слов есть только одна гласная. Но если вы играете, чтобы выиграть как можно меньше догадок, лучше всего сыграть слово, в котором есть две гласные и три согласные: во всех 10 лучших есть две гласные.
Но если вы играете, чтобы выиграть как можно меньше догадок, лучше всего сыграть слово, в котором есть две гласные и три согласные: во всех 10 лучших есть две гласные.
Готов, цель…
Разговор Wordle стратегия: Математика или язык?Другие исследователи, такие как Дэвид Сидху из Университетского колледжа Лондона, пытались определить «лучшее первое слово» с лингвистической точки зрения. В этих усилиях лучший выбор определяется тем, как часто определенные буквы появляются в английском языке, или частотой расположения этих букв в пятибуквенных словах.
Хотя эти подходы благородны, наш анализ выходит за их рамки, фактически выполняя симуляции для всех возможных вариантов слов, чтобы найти лучший тип слова для воспроизведения в первую очередь.
Чтобы провести этот анализ, двое моих студентов, Тао Вей и Канвал Ахмад, создали программу, которая прошла через все 2315 официальных пятибуквенных слов в словаре Wordle . Программа пробовала каждое возможное слово в качестве первого предположения и запускала симуляции для всех возможных решений конечного слова, проверяя, сколько времени потребуется для каждой попытки, чтобы угадать правильное конечное слово — 1,69Всего 2265 симуляций.
Программа пробовала каждое возможное слово в качестве первого предположения и запускала симуляции для всех возможных решений конечного слова, проверяя, сколько времени потребуется для каждой попытки, чтобы угадать правильное конечное слово — 1,69Всего 2265 симуляций.
Затем мы усреднили все попытки для каждого слова, чтобы увидеть, сколько догадок можно ожидать, чтобы получить правильное конечное слово.
Для выполнения этой масштабной симуляции требуется метод выбора оптимального слова при втором и третьем предположениях и т. д.
Чтобы получить наилучшие шансы на каждое последующее предположение, важно выбрать буквы, которые с наибольшей вероятностью появятся в каждой позиции. Таким образом, программа использовала список из 2315 слов, чтобы определить частоту появления каждой буквы.
Получив результаты предыдущего предположения, программа отфильтровала возможные слова до тех, которые соответствуют критериям. Скажем, первое предположение было «парень», и L и E были в правильном положении, а B, O и K не фигурировали в решении. Затем программа сужала список возможных слов до таких, как «лоток» и «сланец».
Затем программа сужала список возможных слов до таких, как «лоток» и «сланец».
Затем программа присваивает оценку каждому слову в этом списке, где оценка представляет собой сумму частоты встречаемости букв. Например, слово «slate» имеет оценку 37 %, потому что буква «S» встречается в полном списке в 5 % случаев, а буква «A» — в 8 %, и так далее. Затем слово с наибольшим количеством баллов отправляется в качестве следующего предположения.
Прогон этой симуляции со всеми возможными первыми предположениями и всеми возможными решениями дал результаты.
Как выиграть
Wordle быстроНо, возможно, вы не хотите каждый раз начинать с одного и того же слова. В этом случае — и если вы хотите выиграть с наименьшим количеством догадок — попробуйте убедиться, что ваша первая догадка состоит из двух гласных, причем одна из них стоит в конце слова.
Если вы просто хотите выиграть в отведенных шести догадках, то вы можете рассмотреть слово с меньшим количеством гласных и, безусловно, слово, которое заканчивается на согласную.
Будем надеяться, что наш математический подход к Wordle не лишил игру всей радости. По крайней мере, это даст вам преимущество, если вы решите сделать дружескую ставку на завтрашнюю игру.
Эта статья была первоначально опубликована Дереком Хорстмайером из Университета Джорджа Мейсона по номеру . Читайте оригинальную статью здесь.
Подпишитесь бесплатно на 9Отмеченный наградами ежедневный информационный бюллетень 0003 Inverse .
Подписываясь на эту рассылку BDG, вы соглашаетесь с нашими Условиями обслуживания и Политикой конфиденциальности
Подпишитесь на нашу рассылку >
Какие слова в Wordle лучше всего угадывать первыми?
- Общий
Есть несколько слов, которые могут быть полезны.
Если вы заядлый игрок Wordle , вы, наверное, придумали множество советов и приемов, которые помогут правильно угадать слово дня всего за несколько попыток.
Но для новичков в игре или тех, кто только пытается решить головоломку за шесть попыток или меньше, есть несколько стратегий, которые вы можете попробовать, и они могут вам помочь. Самая очевидная и, возможно, самая полезная стратегия — выбирать первое сильное слово, которое нужно угадывать каждый божий день.
Хотя вполне возможно, что вы можете понять ежедневный Wordle даже с относительно плохим первым словом, это, очевидно, помогает создать прочную основу для остальных догадок. При этом, вот некоторые из лучших слов, которые нужно угадать первыми из 9.0003 Слово.
Хорошей стратегией для первого слова является использование как можно большего количества гласных. Есть несколько пятибуквенных слов с четырьмя гласными, что ставит их на первое место в списке кандидатов на ежедневное использование в Wordle. Ниже приведен список слов из пяти букв с четырьмя гласными, которые вы можете использовать в следующий раз, когда будете играть.
Ниже приведен список слов из пяти букв с четырьмя гласными, которые вы можете использовать в следующий раз, когда будете играть.
- OUIJA
- ADIEU
- AUDIO
- LOUIE
- AULOI
- AUREI
- URAEI
- OURIE
- MIAOU
Связанный: Каков сегодняшний ответ Wordle ?
Конечно, вероятность того, что любое из этих слов является настоящим Wordle, крайне мала. Но, используя несколько гласных одновременно, вы, вероятно, сможете более четко увидеть, какими словами Wordle может и не может быть. Например, если вы сначала угадаете «АУДИО» и не получите ни желтых, ни зеленых букв, вы будете знать, что в правильном слове, скорее всего, есть буква «е», что значительно сократит список возможных слов.
Некоторые люди также предлагают угадывать одно и то же первое слово каждый день, чтобы увеличить свои шансы на правильное угадывание Wordle с первой попытки. Другие предпочитают менять его каждый день.